Unter dem Motto »Bleeding-edge for the Enterprise« fand die »7th International Software Development Conference« QCon vom 25. bis 29. Juni 2018 in New York statt. Wir waren dabei und geben nachfolgend einen Überblick und unseren Eindruck der besuchten Vorträge.

Inhalt:
- Bleeding-edge for the Enterprise
- Workshops
- Keynotes
- Vorträge
- Software Updates in an Orchestrated World
- WebAssembly 101
- Understanding Code Performance in Production
- From Software Development to Machine Learning
- Skype’s Journey From P2P
- Explaining Artificial Intelligence to Schoolchildren
- The Story of Teams, Autonomy, and Servant Leadership
- AutoCAD & WebAssembly: Moving a 30 Year Code Base to the Web
- Breaking Codes, Designing Jets and Building Teams
- Empowering Agile Self-Organized Teams With Design Thinking
- Software Is Eating the World, ML Is Going to Eat Software
- Einschätzung
Bleeding-edge for the Enterprise
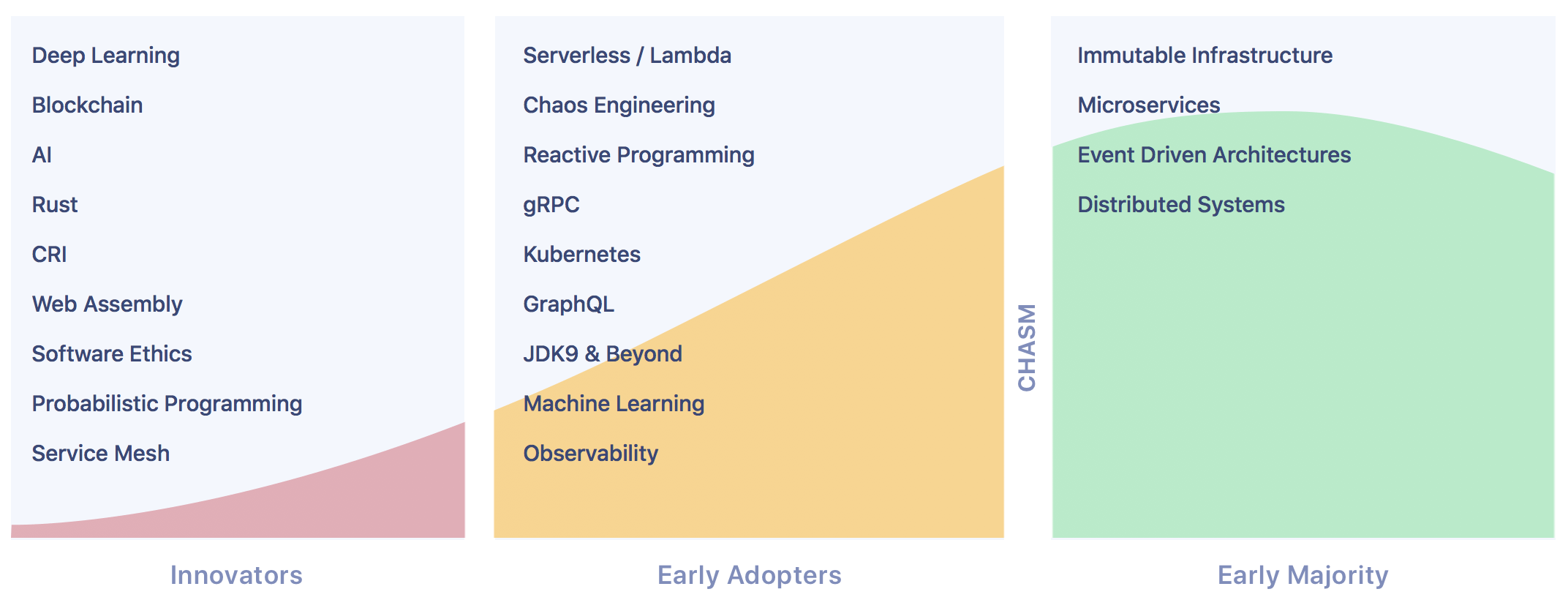
Nach der QCon 2015 in San Francisco stand dieses Jahr New York für uns auf der Agenda. Mit dem Veranstaltungsort direkt am Times Square war die Konferenz im wahrsten Sinne des Wortes am Puls der Zeit. Die Veranstaltung ist »designed for senior software engineering leaders« und bot den über 900 Teilnehmern 117 Vorträge von 143 Rednern aus folgenden Themenbereichen:
 © C4Media Inc | InfoQ.com
© C4Media Inc | InfoQ.com
Ob nun jedes Thema oder jeder der genannten Themenbereiche wirklich »bleeding-edge« ist, hängt natürlich immer auch von der eigenen Positionierung innerhalb der »Technology Adaption Curve« ab. Unserer Einschätzung nach ist die QCon schon sehr nah am Puls der Zeit und das nicht nur geografisch. Tech Leads und ähnliche Rollen aus den Entwicklungsabteilungen von führenden Firmen im Software Engingeering wie Facebook, Netflix & Co. berichten hier über das, was jeweils wirklich schon im Einsatz ist. Ein schönes Beispiel hierzu ist das Thema Machine Learning. Während unserer Einschätzung nach die meisten Firmen, wenn überhaupt, noch dabei sind, das Thema zu verstehen, im besten Fall damit herum experimentieren, zeigte Facebook auf der Konferenz, wie sie es schon zur konkreten Produktivitätssteigerung in der eigenen Entwicklungsabteilung und zur Optimierung des Cache-Managements in der Infrastruktur einsetzen – Use Cases die wir so, zumindest vorher, noch nicht gesehen hatten.
Waren Microservices 2015 als sogenannte »Innovators« in QCons »Technology Adaption Curve« noch beherrschendes Thema, so befinden sie sich nun in der »Early Majority« (siehe Grafik oben). Folglich gab es zwar noch einen Track zum Thema, hier lag der Fokus der Vorträge dann aber auch auf sehr konkreten Anwendungs- und Betriebsthemen derselben.
Die beherrschenden diesjährigen Themenbereiche waren entsprechend auch wieder aus den Bereichen »Innovators« und »Early Adopters«, insbesondere Serverless, Chaos Engineering und Machine Learning sowie Blockchain, Rust, Web Assembly und Software Ethics. Wobei die Einstufung des letzten Themenbereichs innerhalb »Innovators« uns dann doch verwundert hat, da wir Ethik als relevante Dimension der Leistungsbeurteilung beispielsweise nun schon seit über 10 Jahren propagieren und nicht unbedingt als Innovation sehen würden.
Workshops
Die ersten zwei Tage der Konferenz waren ausschließlich Workshops gewidmet. Themen reichten von Serverless über die Programmiersprache Go und Python-basierte AI bis zu Microservices »in Aktion«. Neben diesen eher technologischen Themen gab es auch wieder Workshops zu den »weicheren« Aspekten rund um Softwareentwicklung.
From Developer to Architect
In diesem Workshop wurde aufgezeigt, was einen Softwarearchitekten von einem Softwareentwickler unterscheidet, beziehungsweise was die Rolle des Architekten an Aufgaben mit sich bringt. Die Wichtigkeit dieser Rolle in Softwareentwicklungsvorhaben haben wir ja bereits an anderer Stelle aufgezeigt.
Zunächst wurden hier die organisatorischen und kommunikativen Aspekte der Architektenrolle herausgestellt. Dass ein Architekt viel kommunizieren muss, mag einleuchten, bedeutet aber andererseits auch, dass er viel Zeit in Besprechungen verbringt. Interessant ist hier die Analogie, dass Architektur eine Geschichte ist, die erzählt werden muss. Wer das als Entwickler nicht mag, sollte sich eventuell überlegen, ob er wirklich Architekt werden möchte, beziehungsweise weiß die Arbeit, die der Architekt dem Entwickler damit abnimmt, dann vielleicht auch ganz anders zu schätzen.
Mit den organisatorischen Aspekten sind dann häufig auch Budgetfragen verbunden, die ein Architekt zu beantworten hat. Und wo es um Geld geht, wird es schnell politisch, weshalb ein Architekt auch wissen muss, wie er welche Botschaft wann an wen sendet. Hier kann Ben Thompsons Social/Communication Map helfen.
Auch wurde angesprochen, dass die Entwicklung zum Architekten in der Praxis ja (leider) häufig über Versuch und Irrtum erfolgt. Dass Architekten in ihrer Laufbahn aufgrund der tendenziell langläufigen Natur ihrer Arbeit häufig nur wenige Architekturen von Anfang bis Ende bearbeiten können, erschwert dies zusätzlich. Wobei der Referent dabei auch die interessante Frage stellte, was denn eigentlich die Definition-of-Done einer Architektur ist? Neal Fords Architektur Katas wurden als ein Element genannt, um Architekturentwicklung gefahrlos üben zu können. Denn ein guter Architekt wird man, in dem man an Architekturen arbeitet:
»How do we get great designers? Great designers design, of course.« –Fred Brooks
Ein weiterer Teil des Workshops war der Technologieauswahl gewidmet. Auch wenn Architektur nicht gleich Technologie ist, so ist die Technologieauswahl doch häufig Architektenaufgabe. Der Architekt sollte hierbei aber die eigentlichen Ziele nicht aus dem Auge verlieren. So ist beispielsweise die Testabdeckung in der Regel wichtiger, als welches Testing-Framework schlussendlich zum Einsatz kommt. Da Technologiefragen gerade unter Entwicklern gerne auch ideologisch geführt werden, ein guter Tipp vom Referenten:
»Avoid resume-driven decisions!« –Nathaniel T. Schutta
Üblicherweise verantwortet ein Architekt die sogenannten nicht-funktionalen Anforderungen, weshalb ein weiterer Block auch diesen sich häufig widersprechenden Attributen einer Software gewidmet war, wie zum Beispiel:
- Wartbarkeit
- Skalierbarkeit
- Verlässlichkeit
- Sicherheit
- Ausrollbarkeit
- Einfachheit
- Nutzbarkeit
- Kompatibilität
- Fehlertoleranz
- Modularität
- …
Aus Sicht des Referenten sollte ein Architekt hier aber besser von Qualitätsmerkmalen reden. Denn welcher Kunde zahlt schon gerne für etwas, das keine Funktion erfüllt und was er üblicherweise nicht direkt sieht?
Da Architekturentscheidungen getroffen werden, ob man es will oder nicht (»Accidental Architecture«), ist es wichtig, die Rolle des Architekten zu klären. Die besten Architekturen entwickeln sich nach aktuellem Kenntnisstand evolutionär (»Evolutionary Architectures«) durch
- Nutzung von Feature Toggles
- sowie hypothesengestützte Entwicklung,
- Einsatz von Fitnessfunktionen
- und Chaos Engineering.
In Anlehnung an Winstons Churchills Ausspruch zur Demokratie gab der Referent zum Thema Prozesse zum Abschluss noch ein Zitat mit Augenzwinkern auf den Weg:
»Agile is the worst form of software development, except all other.« –Nathaniel T. Schutta
Insgesamt ein solider Grundlagen-Workshop zur Rolle des Architekten, wenn auch nicht unbedingt »bleeding-edge«. Ein wenig mehr Bezug zu aktuellen Fragestellungen der Softwarearchitektur, wie beispielsweise Architektur im Kontext agiler Softwareentwicklung hätte den Workshop noch abgerundet.
Coaching the Team System
Teams verändern sich. Hilfestellungen hierzu bot dieser Workshop. Wurde früher versucht, Teams wie Systeme möglichst stabil zu halten (»Never change a running/winning…«), so setzt sich immer mehr die Erkenntnis durch, dass wir damit eher das Gegenteil erreichen, da wir so im Moment der Veränderung schlecht vorbereitet sind: Wie sollen wir gut in etwas sein, was wir nicht regelmäßig praktizieren?
»Teams change. Better get good at it.« –Heidi Helfand
Die Referentin zeigte zunächst auf, dass bereits wenn eine Person ein Team verlässt oder hinzu kommt, eine neue Teamsituation entsteht, auf die wir eingehen müssen. Veränderungen passieren dabei auch noch auf verschiedenen Ebenen:
- Person
- Team
- Gilde, Stamm, Tribe – Gruppierungen einzelner Rollen, beispielsweise »alle Entwickler«
- Abteilung
- Unternehmen
Außerdem folgen auch Veränderungen einem Zyklus. Dreht es sich während der Entstehung eines Teams beispielsweise eher um Fragen des Onboardings neuer Mitarbeiter, so stehen heranwachsende Teams vor anderen Herausforderungen. Hier muss dann zum Beispiel mit kulturellen Veränderungen umgegangen werden, wenn aus eher chaotischen Startups Hierarchien entwachsen. Reife und stabile Teams benötigen wiederum oftmals eher einen Impuls, um wieder Energie freizusetzen beziehungsweise Veränderungen anzustoßen. Zu jeder dieser Coaching-Herausforderungen gab die Referentin entsprechende Tools mit auf den Weg, beispielsweise die »Market of Skills«-Aktivität, beim Onboarding neuer Mitarbeiter oder die »First-Team«-Aktivität, wenn kulturelle Aspekte geteilt werden sollen.
Googles Projekt Aristotels hat dabei eindrucksvoll gezeigt, dass dies nichts Esoterisches ist, sondern dazu dient, das, was erfolgreiche Teams ausmacht, herzustellen: »psychologische Stabilität«.
Bleibt die Frage, wer im Unternehmen dann eigentlich diese wichtige Rolle des Coaches übernimmt. Die Rolle Teamleitung als »klassische« erste Anlaufstelle für diese Fragen sehen wir hierzu insbesondere in agilen Teams immer häufiger gar nicht mehr genug »auf dem Spielfeld«. Gleichzeitig reduzieren Unternehmen die Rolle des Scrum Masters häufig nach einiger Zeit zum Teil drastisch, da »Scrum ja dann eingeführt ist«. Wir haben schon erlebt, dass ein Scrum Master beziehungsweise agiler Coach für 10 und mehr Teams zuständig war. Idealerweise verfügt jedes Team über diese notwendigen Teamentwicklungs-Skills, aber auch dieser Zustand muss erfahrungsgemäß zunächst hergestellt werden. Und dann ändert sich das Team wieder. Booking.com hat im Vortrag »The Story of Teams, Autonomy, and Servant Leadership« vom Donnerstag (siehe unten) interessanten Einblick in ihren Ansatz dazu gegeben.
Keynotes
Jeder der drei folgenden Konferenztage begann jeweils mit einer Keynote, welche durch Themenwahl und Vortragenden auch immer zum Nachdenken anregen sollte.
Developers as a Malware Distribution Vehicle
Ein »guter« Softwareentwickler vereint bekanntermaßen die drei Eigenschaften Faulheit, Ungeduld und Überheblichkeit. In diesem Vortrag wurde aufgezeigt, dass gerade diese Kombination ihn aber auch besonders empfänglich für Hacker-Angiffe macht.
So hat XcodeGhost in 2015 beispielsweise über 4.000 Apps infiziert und bis zu 1,4 Millionen Opfer pro Tag geschädigt. Dabei wurde von Unbekannten eine infizierte Version von Apples IDE XCode hinter Chinas Great Firewall ausgerollt. Diese hatte prominente Apps wie zum Beispiel WeChat durch einen veränderten Compiler mit Schadcode versehen, wodurch die betroffenden Apps gleich mehrere Angriffsvektoren aufwiesen (Remote Control, Datendiebstahl und mehr). Der Referent brachte hier noch eine Vielzahl weiterer Beispiele, von versehentlich auf Github publizierten Zugangsdaten des Fahrdienstleisters Uber bis zu einem Phishing-Angriff auf einen Entwickler der Financial Times. Im ersteren Fall gelangten Millionen Daten von Millionen Fahrgästen und Fahrern von Uber an die Öffentlichkeit. Im letzteren Fall wurden zwar nur kurzzeitig falsche Meldungen über Twitter veröffentlicht, ein ähnlicher Fall bei der AP brachte aber beispielsweise den Dow Jones innerhalb von Minuten um 1 % nach unten. Jedes Mal waren Entwickler das Einfallstor für die Hacker. Salesforce.com führte nach Angaben des Referenten einen internen Phishing-Test durch und Entwickler hatten dabei die zweithöchste Klickrate.
Das Schlimme hieran: Compiler-Hacks wie der geschilderte XCodeGhost sind schon mindestens seit dem sogenannten »Ken Thompson Hack« von 1984 bekannt.
Open-Source Software hat dabei noch einen vermeintlich sicheren Status, da der Quellcode ja öffentlich einsehbar und somit nur schwerlich kompromittierbar ist. Aber wer weiß schon, ob das entsprechende npm-Package auch dem Sourcecode auf Github entspricht? Vergangenes Jahr wurden auf diesem Wege beispielsweise 39 infizierte Packages über zwei Wochen via npm verteilt. Und das zieht sich quer durch alle Technologien. So wurden gerade vergangenen Monat 17 infizierte Docker-Images offline genommen. Und Rubys Paketsystem RubyGem hatte in 2016 sein entsprechendes Sicherheits-Debakel. Das lokale Kompilieren des sauberen Quellcodes könnte hier helfen. Das machen aber nur die Wenigsten. Und dann war da ja noch die Sache mit dem Compiler-Hack…
»You cannot trust code which you do not totally control.« –Guy Podjarny
Der Referent konnte verschiedene Gründe aufzeigen, warum gerade Entwickler dazu neigen, Entscheidungen zu treffen, die negative Auswirkungen auf die Sicherheit eines Systems haben:
- Fokus auf Funktion: Sicherheit wird als Einschränkung wahrgenommen.
- Kognitive Beschränkung: Facebook hat seinen initialen Slogan »Move fast and break things« nicht ohne Grund zu »Move fast with a stable infrastructure« geändert.
- Einerseits fehlendes Wissen: Nicht jeder Entwickler versteht alle Sicherheitimplikationen seiner Arbeit.
- Andererseits fühlen Entwickler sich häufig zu sicher (siehe auch die eingangs erwähnten Eigenschaften eines »guten« Entwicklers) und sind damit beispielsweise dann auch schwerer zu schulen.
- »Das passiert mir doch nicht«-Mentalität, dabei passieren Sicherheitsvorfälle jedem.
Als mögliche Gegenmaßnahmen wurde Folgendes empfohlen:
- Systematisches Lernen aus vergangenen Fehlern
- Sicherheitskontrollen automatisieren
- »Make it easy to be secure«
- Zutritt »wie die Großen« managen, beispielsweise
Die Keynote war ein gelungener Einstieg in den ersten Konferenztag und durchaus ein Augenöffner für gewisse Sicherheitsthemen.
A Brief, Opinionated History of the API
In der zweiten Keynote nahm sich Joshua Bloch, Chief Java Architect von Google, vormals Distinguished Engineer für Sun Microsystems und Autor unter anderem von Effective Java, die Geschichte der API (Application Programming Interface) vor und brachte dabei Erstaunliches zutage.
Bereits 1948 erwähnten Goldstine und von Neuman erstmals eine »Subroutine Library« in ihrer theoretischen (!) Abhandlung über das Programmieren eines sogenannten »Electronic Computing Instruments«. Wilkes hat dann 1951 mit Wheeler und Gill Programmbibliotheken mit dem ersten Text zur Computerprogrammierung überhaupt »Preparation of Programs for Electronic Digital Computers« praktisch eingeführt und wurde unter anderem dafür 1967 mit dem Turing Award ausgezeichnet. Schon damals stellten sie fest:
»Documenting [APIs] is hard.«
Außerdem sollten Programmbibliotheken schon damals Komplexität vor dem Nutzer verbergen. APIs sind natürlich keine Programmbibliotheken, sondern heute losgelöst von ihnen zu sehen. Eine Programmbibliothek hat aber eine entsprechende Schnittstelle (Interface), um die Applikation programmatisch einzubinden. Somit darf man die Programmbibliothek durchaus als Vorläufer der API ansehen. Selbiger Begriff wurde dann erstmals ab 1968 genutzt.
Der Wert einer (guten) API liegt darin, dass die Implementierung geändert werden kann, ohne dass der Nutzer davon etwas merkt. Der Lebenszyklus einer API ist also losgelöst von der Implementierung: »Write once, run anywhere«. Daraus ergibt sich auch der folgende »Test«, ob eine Schnittstelle als API zu verstehen ist oder nicht:
- Es wird ein Set an Operationen bereitgestellt, welche durch ihre Ein- und Ausgaben definiert sind.
- Re-Implementierung ohne Beeinträchtigung des Nutzers wird unterstützt.
Da das vielleicht etwas abstrakt ist, brachte der Referent dann historische Beispiele für entsprechende APIs, die vielleicht nicht jeder bisher auch als solche verstanden hat:
| API | stabil seit |
| Fortran II standard Bibliothek für mathematische Funktionen | 1958 |
| C-Standard-Bibliothek | 1975 |
| Unix System Calls | 1975 |
| DEC VT100 Escape Sequenzen | 1978 |
| IBM PC BIOS | 1981 |
| MS-DOS Befehlszeilen Interface “Prompt” | 1981 |
| Hayes AT Befehlssatz für Modems | 1982 |
| Windows-32 | 1993 |
Viele der oben genannten Beispiele sind heute noch im Einsatz. Der Hayes AT Befehlssatz für Modems findet sich heute noch in fast allen Handys. Und die Standardisierung und Re-Implementierungsmöglichkeit des IBM PCs in Kombination mit MS-DOS haben die Ära der PCs der 1980er Jahre begründet, von der wir auch heute noch zehren. WINE ist wiederum ein schönes Beispiel für eine Re-Implementierung einer API ohne Beeinträchtigung des Nutzers, in dem Fall der Windows-32-API auf unixoiden Systemen. Genauso bilden die C-Standard-Bibliothek und die Unix System Calls das Fundament unserer heutigen digitalen Welt, findet sich doch dank Android ein (freies) Unix in mittlerweile Milliarden von Geräten:
»APIs are the glue that connect our digital universe.« –Joshua Bloch
Bislang war die Re-Implementierung von APIs rechtlich unproblematisch. Durch den Rechtsstreit von Oracle mit Google ändert sich die Situation zumindest in den USA derzeit. Oracle wirft Google vor, dass deren Re-Implementierung der Java Standard Edition Bibliothek für das Android Betriebssystem Oracles Copyright und Patentrechte verletze. Der Prozess läuft bereits seit 2012 und durch mehrere Instanzen. Der aktuellste Entscheid spricht sich für Oracle aus, wodurch APIs derzeit in den USA quasi Copyrightschutz besitzen und nicht ohne Zustimmung des Autors frei re-implementiert werden sollten. Sollte sich hieran nichts mehr ändern, wird unserem digitalen Universum das zusammenhaltende Element entzogen.
Der Referent war in den Gerichtsprozessen als Gutachter tätig und hat sich auch in diesem Vortrag entsprechend für die weiterhin freie Implementierbarkeit von APIs ausgesprochen, weshalb er den Vortrag auch als »opinionated« benannt hat.
Vorträge
Software Updates in an Orchestrated World
Dieser Vortrag lief innerhalb der »Sponsored Tracks«, wurde also von einem Produkthersteller und Sponsor der QCon, in diesem Fall der Firma JFrog durchgeführt.
Der Referent griff den für uns auf der Konferenz durchgängig erkennbaren Faden auf, dass es sicherer ist, oft und schnell zu releasen, als die Systeme stabil zu halten. Aufhänger hierfür war die zunehmende Komplexität der Systeme, die wir entwickeln. Insbesondere, da der Großteil eines Systems üblicherweise aus externer Software besteht, wie wir hier am Beispiel der freien, webbasierten Projektmanagementsoftware Redmine exemplarisch nachgestellt haben:
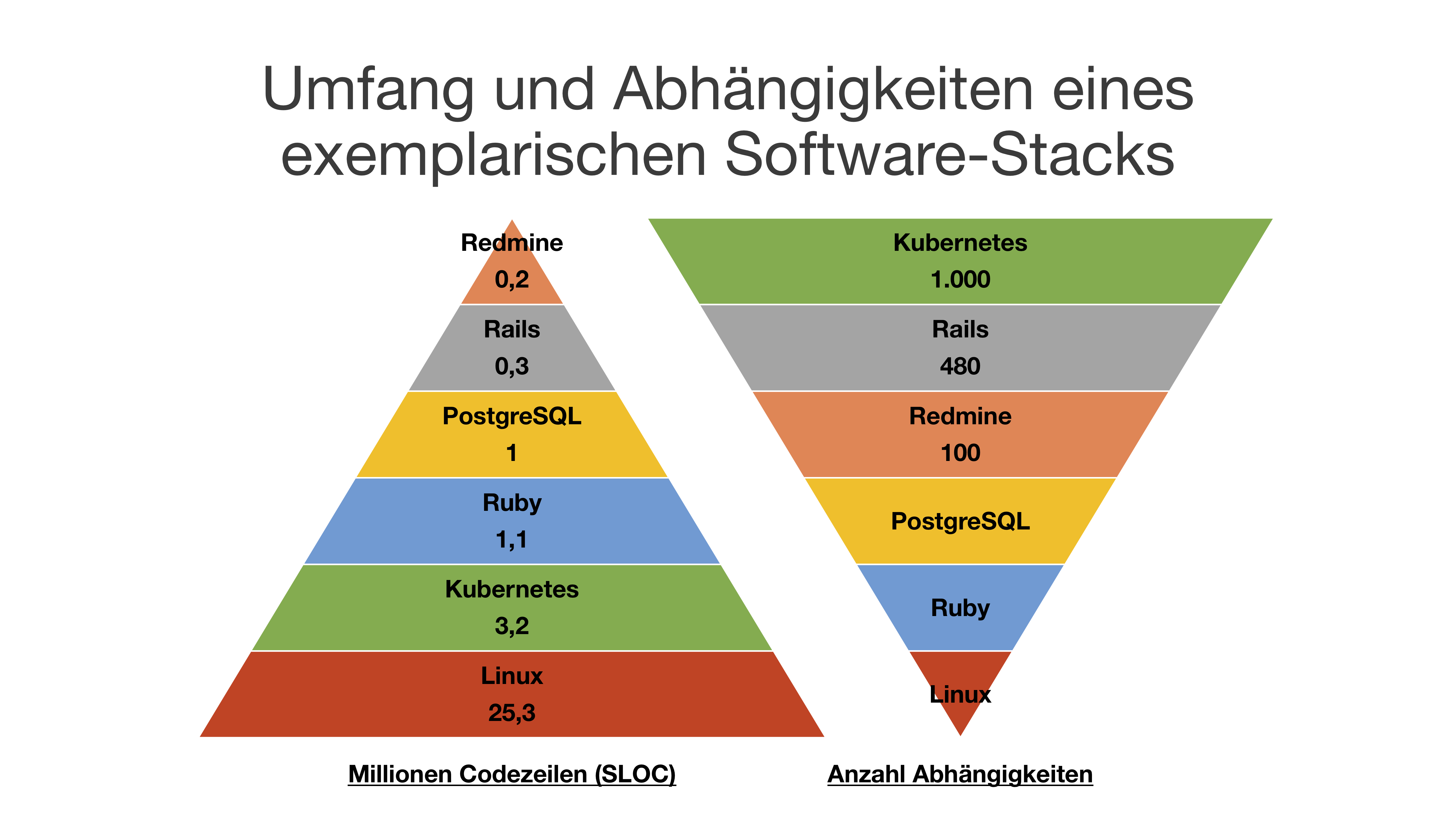
Die eigentliche Anwendung ist hier mit 200.000 Codezeilen beziehungsweise 1 % des Gesamtumfangs nur die Spitze des Eisbergs. 99 % der Anwendung sind Fremdcode, der aber auch verwaltet und insbesondere aktuell gehalten werden will. Die Abhängigkeiten machen die Situation dabei besonders brisant: löst man die rund 1.000 Abhängigkeiten von Kubernetes auf, so wächst allein diese Software schon auf stolze 35 Millionen Codezeilen an, wird also größer als das Betriebssystem.
Bei den exemplarischen 1.580 Abhängigkeiten des oben gezeigten Beispielsystems wäre man 4 Jahre mit Updates beschäftigt, würde man nur eine Abhängigkeit pro Tag aktualisieren. Natürlich bündelt man das in der Regel analog zu Microsofts Patchday. Trotzdem muss der gesamte Softwarestack nach Updates entsprechend getestet werden, was in der Regel einen Großteil des Aufwands ausmacht.
Artefakt-Repositories wie Sonatypes Nexus und JFrogs Artifactory helfen bei der Verwaltung dieser Vielzahl von Abhängigkeiten und somit letztlich bei der Fragestellung, wie man den Überblick über einen komplexen Softwarestack von tausenden von (Open Source) Systemen heutzutage behält. Dazu kommt jedoch noch die zunehmende Komplexität des Bereichs Cybersecurity, schön dargestellt anhand Henry Jiangs »Map of Cybersecurity Domains«. Hier wird erkennbar, dass es nicht mehr nur mit Updates der Fremdsoftware alleine getan ist. Risk-Management, Sourcecode Scans, Vulnerability Checks, Architectural Fit und so weiter wollen und müssen für den Fremcode ebenso bedacht sein:
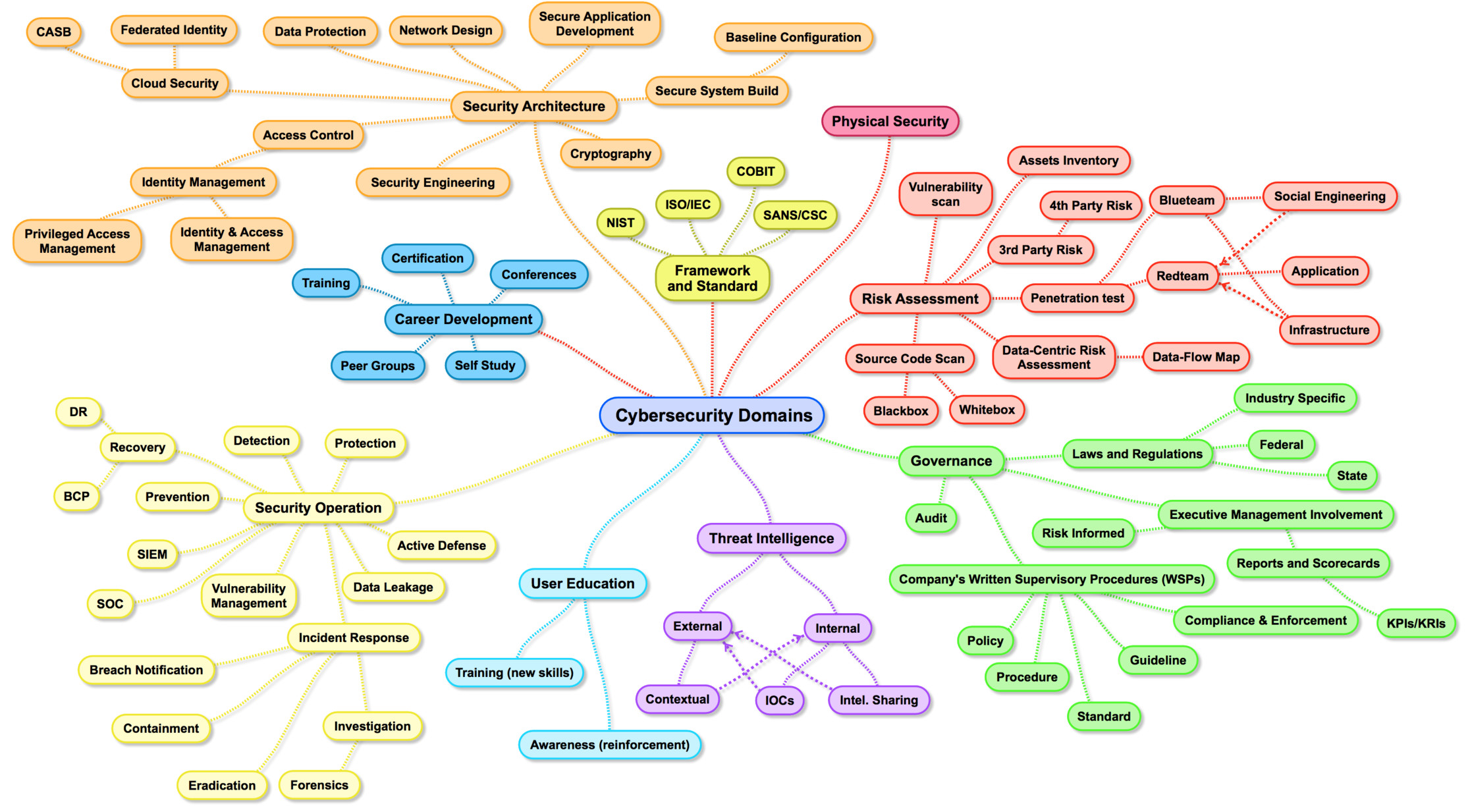 © Henry Jiang | https://www.linkedin.com/pulse/map-cybersecurity-domains-version-20-henry-jiang-ciso-cissp
© Henry Jiang | https://www.linkedin.com/pulse/map-cybersecurity-domains-version-20-henry-jiang-ciso-cissp
Die Produkthersteller erweitern ihre Portfolios natürlich entsprechend. So bietet JFrog beispielsweise mittlerweile auch Security Scans der Artefakte an. Der bisherige Platzhirsch Nexus wird dabei langsam von Artifactory überholt:
 Datenquelle: Google Trends | https://www.google.com/trends
Datenquelle: Google Trends | https://www.google.com/trends
Der Vortrag hat deutlich gemacht, dass das Lifecycle-Management immer wichtiger, aber auch immer aufwändiger wird.
WebAssembly 101
WebAssembly könnte die Art und Weise, wie wir »Web Apps« schreiben, revolutionieren. Der Vortrag gab dem Namen (»101«) folgend einen guten Einstieg in das Thema.
WebAssembly ist ein binärer Befehlssatz, also eine Art Maschinensprache. Der Befehlssatz gilt allerdings nicht für einen speziellen Prozessor, sondern für eine virtuelle Maschine, welche von einer Arbeitsgruppe des World Wide Web Consortium (kurz W3C), dem Gremium zur Standardisierung der Techniken im World Wide Web, verabschiedet wird. Dadurch ist diese virtuelle Maschine auch bereits in allen modernen Browsern vorhanden, wodurch diese zusätzlich zu JavaScript eine weitere Laufzeitumgebung erhalten.
Da es in der Geschichte des Webs schon ähnliche Versuche gab, von Java Applets über Silverlight und Flash bis zu ASM.js und natürlich auch JavaScript, ist eine Abgrenzung hilfreich:
- WebAssembly ist keine Programmiersprache und kein neuer Browser;
- es soll weder JavaScript ablösen, noch ist es so etwas wie Flash oder Java Applets.
- Ohne einen entsprechenden Host funktioniert die Technologie nicht,
- wobei der Host nicht auf das Web beschränkt ist: alles kann ein WebAssembly Host sein.
- WebAssembly ist bislang noch im MVP-Status und dadurch
- weder multi-threaded, was sich mit Web Workern aber umgehen lässt,
- noch garbage-collected, was erklärt, warum Java noch nicht zu WebAssembly kompilieren kann.
Aufgrund der Eigenschaften von WebAssembly, wie zum Beispiel Geschwindigkeit, Portabilität, Effizienz und Sicherheit, sind Anwendungsfälle insbesondere im Umfeld Mobile, IoT sowie grundsätzlicher bei leistungsstarken Web-Anwendungen zu sehen.
Ziel ist dabei nicht, dass direkt in WebAssembly programmiert wird, da es sich wirklich um Binärcode handelt:
20 00
42 00
51
04 7e
42 01
05
20 00
20 00
42 01
7d
10 00
7e
0b
Es gibt zwar auch eine textuelle Entsprechung zu dem oben gezeigten Binärcode, also quasi Assemblercode, aber auch darin wollen wir heute nicht mehr wirklich direkt programmieren:
get_local 0
i64.const 0
i64.eq
if i64
i64.const 1
else
get_local 0
get_local 0
i64.const 1
i64.sub
call 0
i64.mul
end
Ziel ist vielmehr, dass die gängigen Compiler neben den Prozessorarchitekturen, für die sie sowieso schon kompilieren können, also beispielsweise ARM32 oder x86-64 zusätzlich auch für WebAssembly kompilieren können. Für C/C++ und Rust sind bereits entsprechende Kompiler vorhanden. Das folgende C-Programm wurde beispielsweise entsprechend für WebAssembly kompiliert, um den voran gezeigten Binär- beziehungsweise Assemblercode zu erhalten:
int factorial(int n) {
if (n == 0)
return 1;
else
return n * factorial(n-1);
}
Der Ablauf, um ein Programm in WebAssembly zu erstellen und nutzen ist somit wie folgt:
- Schreiben oder portieren eines Programms in einer Programmiersprache, welche WebAssembly unterstützt – derzeit C/C++, Rust und Go seit Version 1.11 zumindest experimentell.
- Entsprechendes Kompilieren des Programms nach WebAssembly (WASM).
- Das Kompilat wird dann über einen entsprechenden Webserver, der WebAssembly unterstützt, den sogenannten Host, ausgespielt
- und kann dann, wie eine Webseite, von einem Browser, der WebAssembly unterstützt (Chrome, Edge, Firefox und WebKit/Safari), abgerufen werden.
Der Klassiker »helloWorld.c«
#include <stdio.h>
int main(int argc, char ** argv) {
printf("Hello, world!\n");
}
kompiliert nach WebAssembly sieht als statische Seite im Browser natürlich noch unspektakulär aus:
Der in C geschriebene Editor VIM wurde aber auch schon erfolgreich nach WebAssembly kompiliert und ist darüber im Webbrowser lauffähig, was zeigt, welches Potential in der Technologie steckt:
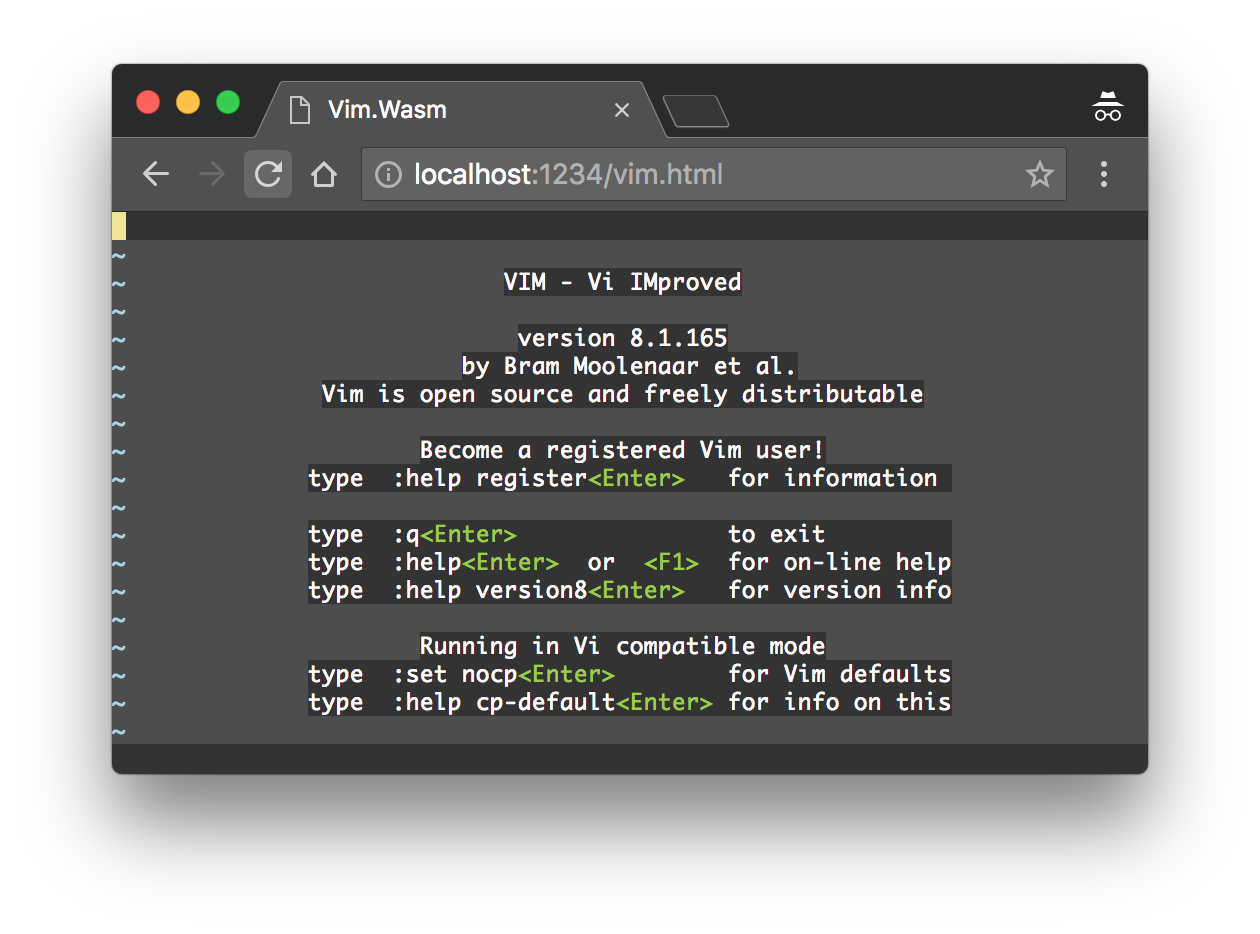 © rhysd | https://rhysd.github.io/vim.wasm/
© rhysd | https://rhysd.github.io/vim.wasm/
Die Codebasis von VIM ist über 25 Jahre alt und umfasst mehr als 750.000 Zeilen, wurde aber in weniger als einer Woche von einem Entwickler nach WebAssembly portiert – inklusive Erlernen des notwendigen Toolings.
Im Vortrag »AutoCAD & WebAssembly: Moving a 30 Year Code Base to the Web« vom Donnerstag (siehe unten) gibt es weitere Details zu einem noch größeren Portierungsvorhaben. Die Spiele-Engine Unity ist wohl auch schon entsprechend portiert, »Tanks« lässt sich als WebAssembly-Demo zumindest schon im Browser spielen. Vielleicht ergibt sich so auch eine Lösung für das Cobol-Problem? Wir sind gespannt, ob und wann die ersten Cobol-Compiler WASM erzeugen können…
Understanding Code Performance in Production
Dieser Vortrag innerhalb der »Sponsored Tracks«, wurde von der Firma AppDynamics durchgeführt.
Produktive Umgebungen sind häufig anders als Entwicklungsumgebungen, da beispielsweise nicht jeder Entwickler auch zwangsläufig Zugang zu den entsprechenden Produktivsystemen seiner Applikation bekommt. Gleichzeitig verlagern sich die Erwartungen an den Betrieb von Applikationen durch Ansätze wie DevOps und You-Build-it-You-Run-it in Richtung Entwicklung. Hier kann sogenanntes Application Performance Monitoring dem Entwickler wichtige Informationen über das Verhalten seiner Software in Produktion liefern. Üblicherweise wird dabei bereits zur Entwicklungszeit eine entsprechende Software in die zu überwachende Applikation integriert, häufig in Form eines Agenten. Diese benötigen natürlich auch Ressourcen, weshalb sie mit bis zu 2 % Performance zu kalkulieren sind.
Am Markt haben sich mehrere Hersteller und Lösungen etabliert. AppDynamics ist dabei in Gartners Magic Quadrant für Application Performance Monitoring im Leaders-Quadranten eingestuft. Darüber hinaus war der Vortrag weitestgehend eine Produktvorführung.
From Software Development to Machine Learning
Bei diesem Vortrag handelte es sich um den Erfahrungsbericht der Transformation eines klassischen PHP-Software-Engineering-Teams hin zu Machine Learning aus Sicht der verantwortlichen Managerin. Der vorliegende Fall war sicherlich ein Extrembeispiel, da das Unternehmen sein Produktportfolio komplett umstellen wollte und die Entwicklung dementsprechend ebenso radikal umgestellt werden musste. Die Referentin hat das Unterfangen nicht ohne Grund mit einer Organtransplantation verglichen.
Die Transformation geschah dabei auf verschiedenen Ebenen:
- Individuum
- Team
- Unternehmen
Auf der Ebene des Individuums musste beispielsweise mit Python eine neue Technologie gelernt werden. Das mag sich zunächst nur nach einer weiteren Programmiersprache anhören, hat aber auch »soziale« Aspekte, da der Senioritätsgrad der Mitarbeiter damit quasi über Nacht abgestuft wurde, weil beispielsweise der vorherige PHP Senior Web Developer nun auf einmal Python Junior Engineer war.
Auf Team-Ebene muss man sich mit geänderten und ganz neuen Rollen auseinandersetzen. Aus einem Web Developer muss ein Machine Learning Engineer werden und aus einem Softwarearchitekt ein Data-Architekt. Ganz neu ins Spiel kommt der Data Scientist, nach Aussage der Referentin eine derzeit viel zu strapazierte Rolle, für die es bislang auch noch keine universelle Definition gibt. Außerdem können ihrer Meinung nach die wenigsten davon auf dem Level eines Software-Engineers entwickeln, da sie sich meist aus dem mathematisch-akademischen Bereich rekrutieren und damit zwar vielleicht gut in Algorithmen sind, aber nicht zwangsläufig wissen, wie man große, langlebige Systeme für den Produktiveinsatz entwickelt.
Aus eigener Projekterfahrung wissen wir, dass die Umstellung eines Teams auf eine neue Technologie zwar machbar ist, eine Organisation aber durchaus einige Jahre beschäftigen kann.
Wer sich selbst tiefer in das Thema Machine Learning einarbeiten möchte, findet hier eine gute Übersicht an Kursen.
Skype’s Journey From P2P
Dieser Vortrag zeigte Skypes Wandel von einer (»der«) P2P-Architektur hin zu einem Server- und Service-basierten Ansatz.
Mit dem ersten Release hat Skype 2003 eine der größten P2P-Architekturen ausgerollt. Jeder Client wurde dabei zu einem Knoten des P2P-Netzes, welcher weitestgehend losgelöst vom Backend operieren konnte. Das Backend bestand primär aus PostgreSQL-basierten Datenbank-Services, die Logik wurde überwiegend im Client implementiert.
 © Bruce Lowekamp | https://www.infoq.com/presentations/skype-p2p
© Bruce Lowekamp | https://www.infoq.com/presentations/skype-p2p
Bezogen auf das CAP-Theorem, wonach in einem verteilten System von den drei Anforderungen Konsistenz (Consistency), Verfügbarkeit (Availability) und Partitionstoleranz nur zwei umfassend erfüllt werden können, konnte so maximale Verfügbarkeit und Partitionstoleranz (»AP«) sichergestellt werden.
Nach der Übernahme 2011 durch Microsoft wurde auch die Architektur hinterfragt. Dabei stellte sich heraus, dass die Welt beziehungsweise die Anforderungen sich geändert hatten. Desktop-Applikationen waren nicht mehr dominant, sondern mobile Anwendungen. Serverkosten hatten sich drastisch reduziert, dafür sollte Messaging beispielsweise auch offline möglich sein. Außerdem wurden Funktionen wie server-weites Suchen oder Vorschläge benötigt. Außerdem erschien es nicht mehr sinnvoll, die Logik im Client vorzuhalten. Die Funktionen des Skype-Clients wurden deshalb in mehreren Teilschritten auf eine verteilte Service-Architektur migriert, welche sich zum Teil natürlich auch bei bekannten Services von Microsoft bedient, beispielsweise MSA für Login:
 © Bruce Lowekamp | https://www.infoq.com/presentations/skype-p2p
© Bruce Lowekamp | https://www.infoq.com/presentations/skype-p2p
Die Migration wurde dabei durch A/B Tests unterstützt, für welche eigens ein sogenannter Experimentation and Configuration Service (ECS) aufgebaut wurde, der mittlerweile bei ganz Microsoft im Einsatz ist.
Skypes ehemalige P2P-Architektur soll ab Herbst 2018 Geschichte sein. Interessant, dass auch ein IT-Gigant wie Microsoft für so ein Migrationsvorhaben immerhin 7 Jahre gebraucht hat.
Explaining Artificial Intelligence to Schoolchildren
Der Referent dieses Vortrags ist als Entwickler bei IBM für deren Programm Watson tätig und hat unter anderem eine web-basierte Lernumgebung rund um Machine Learning für Kinder erstellt. Da Machine Learning in immer mehr Bereiche vordringt, gab es für die anwesenden Entwickler auch gleich ein paar beruhigende Worte von einem, der seit Jahren in dem Umfeld professionell tätig ist:
»Artifical Intelligence adds to a developer’s toolbox, it doesn’t replace him.« –Dale Lane
Ihm ist es wichtig, aufzuzeigen, was Machine Learning als Teilbereich der Künstlichen Intelligenz (Artifical Intelligence) ist, was damit machbar ist und wo die Grenzen sind; und das möglichst auch schon Kindern, da diese zukünftig immer mehr mit entsprechenden autonomen Systemen konfrontiert sein werden.
»Machine Learning is…Learning how to perform a task from a collection of examples.« –Dale Lane
In der Lernumgebung werden Kinder auf spielerische Art und Weise durch die notwendigen Schritte für Machine Learning geführt:
- Sammeln von beispielhaften Daten (Bilder, Zahlen, Texte) für die Aufgabe
- Trainieren des Computers anhand der Beispieldaten (hier erfolgt das Lernen)
- Programmieren einer Anwendung, welche anhand des Gelernten entsprechende Aufgaben ausführt
Im ersten Schritt dreht es sich darum, entsprechende Daten für das jeweilige Vorhaben in ausreichender Menge zu sammeln - zum Beispiel Bilder von Gesichtern. Im zweiten Schritt wird das System dann trainiert. Beispielsweise werden die Bilder in zwei Gruppen von Menschen mit glücklichem und unglücklichem Gesichtsausdruck aufgeteilt. Im dritten Schritt wird über Scratch, die visuelle Programmiersprache für Kinder, welche in der Lernumgebung mit der API von Watson integriert ist, ein einfaches Programm geschrieben. Im genannten Beispiel würden neue Fotos anhand des Gesichtsausdrucks in glücklich oder unglücklich eingeordnet werden.
Wichtig ist dem Referenten dabei insbesondere auch immer wieder die Grenzen von Machine Learning aufzuzeigen. Konkret zum Beispiel die vielen Möglichkeiten, entsprechende Systeme bewusst oder unbewusst mit Vorurteilen anzulernen. Googles Bildersuche, die vor einiger Zeit die Bilder von zwei Afroamerikanern mit der Kategorie Gorilla versah, ist da nur ein Beispiel von vielen.
The Story of Teams, Autonomy, and Servant Leadership
Dieser Vortrag zeigte, wie Booking.com seine Entwicklungsteams im agilen Kontext aufgestellt hat und insbesondere wie die Entwicklung zum aktuellen Status Quo anhand von gesteuerten Experimenten faktenbasiert erfolgte. Dabei war der Fokus insbesondere auf der Rolle Teamleiter – nicht verwunderlich, da diese Rolle in den agilen Entwicklungsansätzen wie beispielsweise Scrum nicht weiter definiert ist, was von vielen so interpretiert wird, als bräuchte es gar keiner Führung im agilen Kontext. Das dem nicht so ist, zeigte der Referent, selbst Führungskraft bei Booking.com, entsprechend auf.
Booking.com ist von acht Mitarbeitern im Jahr 2000 auf aktuell über 15.000 angewachsen, wovon derzeit über 1.500 Mitarbeiter in der IT tätig sind. Um 2014 waren rund 500 Mitarbeiter in der IT. Jedes Team hatte dabei einen Teamleiter und einen Product Owner, die wiederum an einen Senior Teamlead (Abteilungsleiter) und einen Senior Product Owner berichtet haben, welche dann direkt entsprechend an den CTO und CPO berichtet haben:
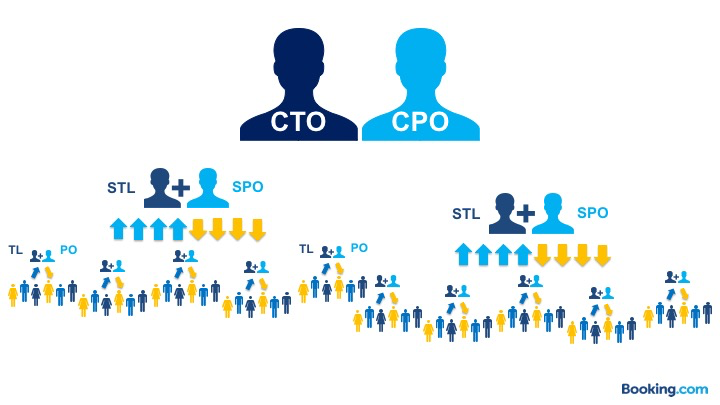 © Georgiy Mogelashvili https://www.infoq.com/presentations/team-autonomy-servant-leadership
© Georgiy Mogelashvili https://www.infoq.com/presentations/team-autonomy-servant-leadership
Aufgabe des Teamleiters war zu rund ⅔ fachliche Mitarbeit im Team und zu rund ⅓ klassische Teamleitungsaufgaben wie zum Beispiel Prozesse, teamübergreifende Kommunikation, Mitarbeiterentwicklung und -leistung. Der Product Owner war für Aufgabenpriorisierung, Backlog-Verwaltung, Metriken und die Kommunikation mit dem Business beziehnungsweise Fachbereich verantwortlich.
Zwischen 2015 und 2016 setzte dann ein extremes Wachstum des Unternehmens ein, was zu einer Verdoppelung der Anzahl der Mitarbeiter in der IT auf rund 1.000 führte. Dies machte auch andere Führungsansätze notwendig, weshalb autonome Teams als Lösungsansatz untersucht wurden. Damit gemeint war, dass Teams ohne Teamleiter arbeiten und alle Teammitglieder gleichermaßen für entsprechende Aufgaben verantwortlich sind. Die bisher vom Teamleiter quartalsweise und 1:1 erfolgten Performance Reviews erfolgten jetzt beispielsweise in einer gemeinsamen Teamsitzung. Spannend, inwiefern das arbeitsrechtlich in Deutschland abbildbar wäre. Der Product Owner als Verantwortlicher für die geschäftlichen Aspekte blieb erhalten, die Teams berichteten innerhalb der IT jetzt direkt an den Senior Teamlead:
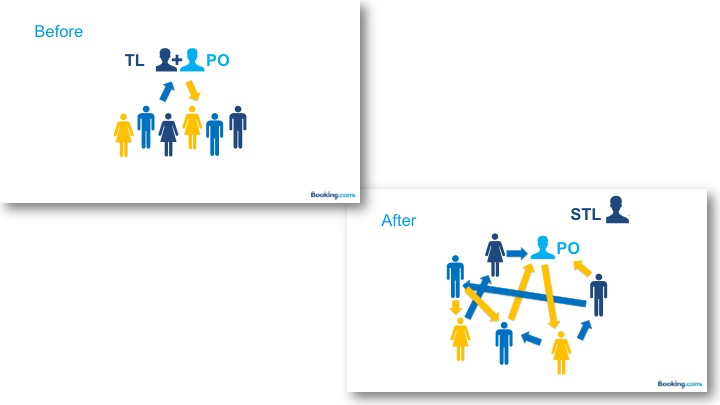 © Georgiy Mogelashvili https://www.infoq.com/presentations/team-autonomy-servant-leadership
© Georgiy Mogelashvili https://www.infoq.com/presentations/team-autonomy-servant-leadership
Das Ganze wurde als Experiment mit 26 von 84 Teams in der IT erprobt. Fokus war dabei auf der Effektivität der Teams analog zu Googles »Perfect Team« und den entsprechenden Metriken.
Booking.com stellte im Laufe des Experiments drei Hauptprobleme fest. Erstens konnte das angestrebte Wachstum in den autonomen Teams ohne entsprechende Unterstützung (durch die Teamleitung) nicht wie gewünscht sichergestellt werden. Zweitens verändern sich Teams (siehe hierzu auch weiter oben zum Workshop vom Dienstag »Coaching the Team System«) und brauchen auch dabei Unterstützung. Drittens waren die Senior Teamleads mit der Vielzahl an Teams, die direkt an sie berichteten, trotz der vermeintlichen Autonomie überfordert.
Den Problemen wäre vermutlich noch zu begegnen gewesen, die wesentliche Kennzahl für Booking.com, das Engagement der Mitarbeiter, ging in diesem Experiment autonomer Teams ohne Teamleitung allerdings erheblich zurück. Es musste also etwas verändert werden. Booking.com versuchte dabei, das Beste aus beiden Ansätzen zu nehmen und kam zu folgender Erkenntnis:
 © Georgiy Mogelashvili https://www.infoq.com/presentations/team-autonomy-servant-leadership
© Georgiy Mogelashvili https://www.infoq.com/presentations/team-autonomy-servant-leadership
Es sollte also autonome Teams, aber mit Teamleiter geben. Hierfür wurde die Aufgabenbeschreibung und insbesondere das Skillprofil der Teamleitung in Richtung Servant Leadership geschärft. Die »neue« Teamleitung hat also keine beherrschende Macht mehr über das Team, sondern ist Teil desselben. Die Performance Reviews werden beispielsweise weiterhin analog zum autonomen Team in einer gemeinsamen Sitzung abgehalten, in der jetzt auch der Teamleiter mit bewertet wird und selbiger auch nur eine Stimme, wie jedes Teammitglied hat.
 © Georgiy Mogelashvili https://www.infoq.com/presentations/team-autonomy-servant-leadership
© Georgiy Mogelashvili https://www.infoq.com/presentations/team-autonomy-servant-leadership
Die Teamleitung arbeitet nach wie vor fachlich mit, aber nur noch unter 50 % und verwendet zukünftig mehr als die Hälfte seiner Zeit auf Personalentwicklung:
 © Georgiy Mogelashvili https://www.infoq.com/presentations/team-autonomy-servant-leadership
© Georgiy Mogelashvili https://www.infoq.com/presentations/team-autonomy-servant-leadership
Da es nicht leicht ist, solche Teamleiter zu rekrutieren, setzt Booking.com agile Coaches ein, um die Teamleiter hier entsprechend zu unterstützen und zu entwicken.
Wichtig auch die Erkenntnis, was Autonomie für Booking.com nicht ist:
- Alleine arbeiten,
- Anarchie oder
- Vernachlässigung.
Die Erkenntnis aus dem gesteuerten Experiment von Booking.com ist, dass Teams auch eine Teamleitung brauchen, andernfalls sinkt die Effektivität. Teamleitung ist hier aber keine beherrschende, sondern eine dienende Rolle mit entsprechenden Aufgaben.
AutoCAD & WebAssembly: Moving a 30 Year Code Base to the Web
Nach der interessanten Einführung in WebAssembly am Dienstag zeigte der Referent dieses Vortrags, wie AutoCAD mittels WebAssembly erfolgreich für das Web portiert wurde. Es handelt sich dabei um eine C/C++-Desktop-Applikation, deren Codebasis rund 15 Millionen Codezeilen umfasst und die bis ins Jahr 1982 zurückreicht.
Als die Entwicklungsmannschaft vor der Aufgabe stand, diese Applikation fit für das Web zu machen, wurde relativ schnell klar, dass ein Neuschreiben aufgrund des Umfangs keine Option war, da es weder nachhaltig ist, zwei Entwicklungslinien für so ein Produkt aufrechtzuerhalten, noch so ein Unterfangen auch nur ansatzweise schnell genug wäre. Ganz zu schweigen vom 2nd-System Effect. Deshalb wurde sich auf die Option der Cross-Kompilierung der Codebasis fokussiert. Es wurden verschiedene Ansätze (Flash, JavaScript, asm.js) probiert, bevor der Durchbruch mit WebAssembly gelang. Als Toolchain kommen dabei Emscripten und WebAssembly Binaryen zum Einsatz.
Mit einem einfachen Kompilieren einer so großen Codebasis war es natürlich nicht getan. Es mussten sowohl an der Codebasis als auch an der Toolchain Anpassungen vorgenommen werden, um folgenden Herausforderungen zu begegnen:
- Kompilier- und Build-Zeit der Codebasis
- Startzeit der Applikation
- Desktop- gegenüber Web-Paradigma.
Die beiden ersten der eben genannten Punkte hängen natürlich direkt mit der umfangreichen Codebasis zusammen. Aber gerade der letzte Punkt, die gegenläufigen Entwicklungsparadigmen zwischen Desktop- und Web-Applikationen, betreffen jeden, der eine entsprechende Software portieren möchte. Als Beispiel wurden synchrone und asynchrone Programmierprobleme im Web genannt. Die Behandlung von blockierenden Aufrufen ist in Desktop-Programmen anders als im Web. Und dann wurde noch Shared Memory angeführt. Desktop-Applikationen erlauben synchrone Schreibzugriffe, da es dort Shared Memory gibt, um Daten zu teilen – im Web gibt es das so nicht.
Für die genannten Probleme fanden die Entwickler bei AutoCAD aber Lösungen, vielleicht nicht in Tagen, so aber in der Regel doch in Wochen oder zumindest Monaten, was in keinem Vergleich zu dem mehrjährigen Neuschreiben der Software steht. Die Applikation steht durch Cross-Kompilierung mittels WebAssembly heute auch als Web-Applikation zur Verfügung.
Breaking Codes, Designing Jets and Building Teams
Dieser Vortrag hätte auch durchaus als Keynote laufen können. Der Referent, Randy Shoup, hat 25 Jahre Erfahrung im Engineering bei den Größen des Silicon Valleys, beispielsweise Director of Engineering bei Google, Chief Engineer bei eBay, Tech Lead bei Oracle und aktuell VP Engineering bei WeWork. Er ist aber auch der Sohn von Richard Shoup, Gründungsmitglied des berühmten Xerox Palo Alto Research Center. Damit hat der Referent natürlich Einblick in die Geschichte des (IT) Engineering wie wenig andere. Und dessen bediente er sich, um anhand von drei Beispielen für sehr effektive Engineering-Teams deren Gemeinsamkeiten herauszuarbeiten.
Sein erstes Beispiel für ein effektives Team betraf die Code-Brecher der britischen Militäreinrichtung Bletchley Park, welche den ersten programmierbaren digitalen Computer bereits 1943 vollständig im Geheimen bauten. Es wird geschätzt, dass dank Bletchly Park der zweite Weltkrieg um zwei Jahre verkürzt und somit 14 Millionen Leben gerettet werden konnten (=> Zweck). Trotzdem es sich um eine Militäreinrichtung handelte, gab es wenig Hierarchie und eine offene => Organisationskultur. Jedes Team war cross-funktional aufgestellt, zwischen den Teams herrschte allerdings absolute Geheimhaltung (also Unabhängigkeit). Aufgrund der sich ständig ändernden Codes mussten auch die Teams permanent lernen und iterieren (=> technische Exzellenz). Dabei waren die Teams extrem divers mit einer Frauenquote von bis zu 75 % (=> Menschen). Bekanntheit hat hierbei natürlich insbesondere Alan Turing erlangt, aber auch Ian Fleming, der Erfinder von James Bond, hat hier gearbeitet.
 © Randy Shoup | https://www.infoq.com/presentations/history-engineering-teams
© Randy Shoup | https://www.infoq.com/presentations/history-engineering-teams
Als zweites Beispiel für außergewöhnliche Engineering-Leistungen wurde Lockheeds sogenannte “Skunk Works” Advanced Developments Gruppe aufgeführt. Seit Gründung 1943 wurden hier Generation um Generation der weltweit am schnellsten und höchsten fliegenden sowie geheimsten Flugzeuge entwickelt, wie zum Beispiel die F-117A Nighthawk. Entgegen dem im modernen Flugzeugbau wohl üblichen Vorgehen, erfolgten Design, Entwicklung und Bau hier innerhalb einer cross-funktionalen Einheit, wo alle beteiligten Rollen eng zusammen saßen (“Co-Location”) und beispielsweise auch der Testpilot eng in den Entwicklungsprozess involviert war (=> Organisationskultur). Dabei war jeder für Qualität verantwortlich:
We made every shop worker who designed or handled a part responsible for quality control. Any worker – not just a supervisor or a manager – could send back a part that didn’t meet his or her standards.
Es wurde schon sehr früh umfassend Gebrauch von Modellen, Simulationen sowie Mockups und Prototypen zum Verifizieren von Hypothesen gemacht (=> Technische Exzellenz). Und auch dieses Team war von Anfang an durch Diversivität geprägt. So war beispielsweise Mary G. Ross als erste amerikanische Ureinwohnerin Gründungsmitglied und Engineer der Skunk Works Group (=> Menschen).
 © Randy Shoup | https://www.infoq.com/presentations/history-engineering-teams
© Randy Shoup | https://www.infoq.com/presentations/history-engineering-teams
Als drittes Beispiel führt Shoup das Xerox PARC an, welches 1970 gegründet wurde und dessen Erfindungen die Grundlage unserer heutigen digitalen Welt sind. Beispielsweise wurden hier Smalltalk als »Mutter der Objektorientierung«, das erste graphische Benutzerinterface mit überlappenden Fenstern als Basis für Apple und Microsoft Windows, die WYSIWYG Textbearbeitung, Ethernet oder auch der Laserdrucker genannt.
Kurzer Einschub an dieser Stelle: Die Erfindung der Computermaus wird auch gerne wahlweise dem Xerox Parc oder Doug Engelbart zugeschrieben, es scheint aber so, dass hier tatsächlich Telefunken aus Deutschland die Nase vorn hatte.
Die => Organisationskultur des Xerox PARC war flach, ohne Hierarchie und versammelte Talente wie Alan Kay, Adele Goldberg und Richard Shoup (=> Menschen) aus der Industrie und dem universitären Bereich.
 © Randy Shoup | https://www.infoq.com/presentations/history-engineering-teams
© Randy Shoup | https://www.infoq.com/presentations/history-engineering-teams
Aus diesen drei Beispielen für extrem effektive Engineering-Einheiten konnte der Vortragende die folgenden gemeinsamen Eigenschaften als Prinzipien effektiven Engineerings ableiten:
- Zweck: Die Teams müssen »groß« denken dürfen, dabei aber fokussiert auf ein wichtiges und motivierendes Ziel für die Organisation sein.
- Organisationskultur: Cross-funktionale »Full Stack« Teams sind für diese Art von Arbeit am effektivsten, das Team muss maximale Autonomie bei minimaler Bürokratie und minimaler zentrale Kontrolle haben; Zusammenarbeit und eine Kultur des Lernens sind weitere Schlüssel zum Erfolg.
- Menschen: Unabhängig von ihrem Hintergrund sind die besten Leute für den jeweiligen Job zu engagieren, dabei ist Diversität wichtig; die Menschen sind gut zu behandeln – schlimm, dass das immer noch erwähnenswert ist, siehe hierzu auch unsere Definition von Leistung, die immer schon die ethische Komponente umfasste.
- Technische Exzellenz: Systemisches Denken und die Suche nach ganzheitlichen Lösungen sind der Schlüssel zu technischer Exzellenz. Dabei muss pragmatisch geliefert werden und konstantes Feedback in alle Prozesse integriert werden.
Vieles davon findet sich heute in den Prinzipien von Agile, Lean oder auch DevOps wieder, wurde dort aber nicht »erfunden«, sondern geht auf Beispiele wie die hier genannten zurück.
Empowering Agile Self-Organized Teams With Design Thinking
Dieser Vortrag gliederte sich in drei Teile. Zunächst stellte der Referent ausführlich seinen grundsätzlichen methodischen Rahmen vor. Anschließend ging er über eine Fallstudie der agilen Transformation einer konkreten Infrastruktureinheit auf Design Thinking für die Gestaltung von Organisationen ein. Abschließend stellte er das theoretische Gerüst von Design Thinking vor.
Der grundsätzliche methodische Rahmen des Referenten war geprägt von »Klassikern« agiler Management-Ansätze.
»People are already doing their best; the problems are with the system. Only management can change the system.« —W. Edwards Deming
»Every system is perfectly designed to get the result that it does.” ― W. Edwards Deming
Aus Sicht des Referenten gibt es nicht den einen und besten Weg, etwas zu organisieren und somit auch nicht »das eine« Organisationsdesign. Er spricht sich auch klar und deutlich gegen klassische autoritäre Managementansätze aus:
»Organizations that operate from the authoritarian, hierarchical, command and control model, where the top leaders control the work, information, decisions, and allocation of resources, produce employees that are less empowered, less creative, and less reductive.« –Creativity and Innovation: The Leadership Dynamics. Journal of Strategic Studies
Dabei hob er auch noch einmal die Quellen von Macht in Organisationen auf Basis von French und Ravens grundlegeneder Arbeit hierzu aus dem Jahre 1959 hervor:
- Legitime Macht durch formale Autorität in einer Hierarchie.
- Wissensmacht durch Expertenwissen auf einem Gebiet.
- Macht durch Vergabe von Belohnung wie beispielsweise finanzielle aber auch immaterielle Anreize (Lob, Erweiterung des Verantwortungsbereiches).
- Macht durch Zwang wie beispielsweise die Möglichkeit, Degradierungen oder Entlassungen vorzunehmen.
- Macht durch Identifikation setzt charismatische Persönlichkeiten voraus, mit denen man sich identifizieren möchte.
- Informationsmacht entsteht durch die Fähigkeit, den Fluss von Informationen und auch Desinformationen in Organisationen steuern zu können.
Womit er zum »Empowerment«, also der Ermächtigung von Mitarbeitern überging. Dies bedeutet für den Referenten, dass eine Gruppe von Mitarbeitern Entscheidungen in einem gewissen Rahmen eigenständig und ohne weitere Rückversicherung beim Management treffen kann. Dem Management kommt hierbei eine besondere Bedeutung zu, weshalb der Referent anhand des sogenannten »Leadership Continuums« verschiedene Führungsansätze diskutierte:
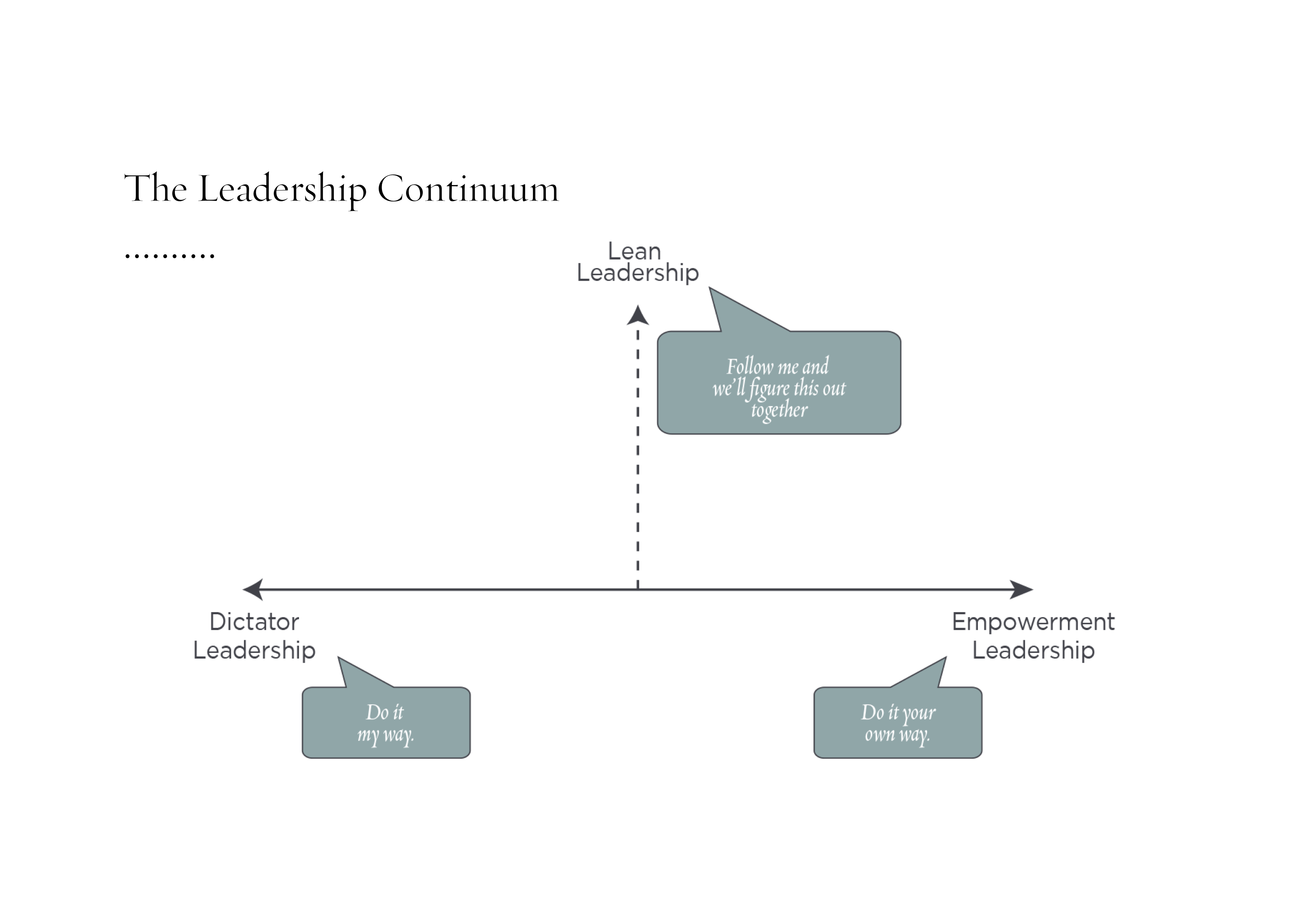 © William Evans | https://www.infoq.com/presentations/agile-self-organizing-teams-design-thinking
© William Evans | https://www.infoq.com/presentations/agile-self-organizing-teams-design-thinking
Beide Enden des dargestellten Kontinuums schnitten dabei nicht besonders gut ab. Diktatorische Führung führt dazu, dass Mitarbeiter sich nicht ermächtigt fühlen und ihnen die Möglichkeit genommen wird, selbst Lösungen zu suchen, welche in der Regel besser sind, da sie näher am Problem sind. Das andere Ende, also vollständige Ermächtigung der Mitarbeiter, ist dabei allerdings auch nicht der Königsweg. Der Referent spricht hierbei auch vom Hippie, der gerade noch Ziele vorgibt und dann verschwindet. Dabei ist für die Mitarbeiter dann häufig keine Strategie erkennbar und es wird wenn überhaupt noch lokal optimiert.
Der Lean Leader hingegen:
- Klärt die Vision und Absicht, also das Warum und Was,
- benennt dabei aber auch die Grenzen und
- vergibt Entscheidungsbefugnisse.
- Er lebt entsprechendes Verhalten vor und
- erzeugt Vertrauen.
- Er bevorzugt Experimente, die auch scheitern können, statt Lösungen vorzugeben.
Der erste Teil des Vortrags schloß mit dem folgenden Zitat ab:
»Individuals and teams closest to the problem, armed with unprecedented levels of insights from across the network, offer the best ability to decide and act decisively.« -General Stanley McChrystal
Interessanterweise spiegelt dieses Idealbild die Situation in Teilen der US-Armee, einer bis dato doch sehr hierarchischen Organisation wider, die sich aber aufgrund geänderter Rahmenbedingungen auch entsprechend an ein neues Führungs- und Organisationsprinzip angepasst hat.
Ausgangssituation der Fallstudie im zweiten Teil des Vortrags war folgendes, wohlbekanntes Spannungsfeld zwischen Fachbereich und IT-Infrastruktur-Entwicklungsteam eines großen Pharmaunternehmens, welches nach Wasserfall-Modell arbeitete:
»You deliver last years tech, in twice the time, for three times the price, and a fraction of the value!«
Nur sechs Wochen nach Umstellung auf eine agile Arbeitsweise konnten bereits folgende Erfolge vermeldet werden:
- Reduzierung der Lead Time für Services von 9 Monaten auf Tage, häufig Stunden.
- Reduzierung ungeplanter Arbeit von 64 % auf 28 %.
- Erhöhung der Zufriedenheit des Fachbereichs um 72 %.
Dies wurde folgendermaßen erreicht:
- Aufsetzen eines Kanban-Systems
- Visualisierung aller Arbeit im Team
- Messen des Wertstroms
- Identifizierung aller Schritte, insbesondere Verschwendung (Frei-/Übergaben)
- Einbeziehung der Anwender
- Einbindung relevanter Stakeholder (Compliance, Security, Finance, …)
- Durchführung einer Designstudie für den neuen Prozess
- Prototypisierung, Testen, Messen und Lernen für diesen neuen Prozess
- Minimum Viable Services entwicklen
- Iterieren, Testen, Messen, Lernen, Iterieren, Wiederholen
Der Wertstrom-Messung kam dabei eine besondere Bedeutung zu, denn darüber lässt sich:
- Der Grund für Falschbedarf erkennen.
- Verschwendung im System identifizieren, wie zum Beispiel
- Warteschlangen
- Unnötige Freigaben
- Rückgaben und Nacharbeiten.
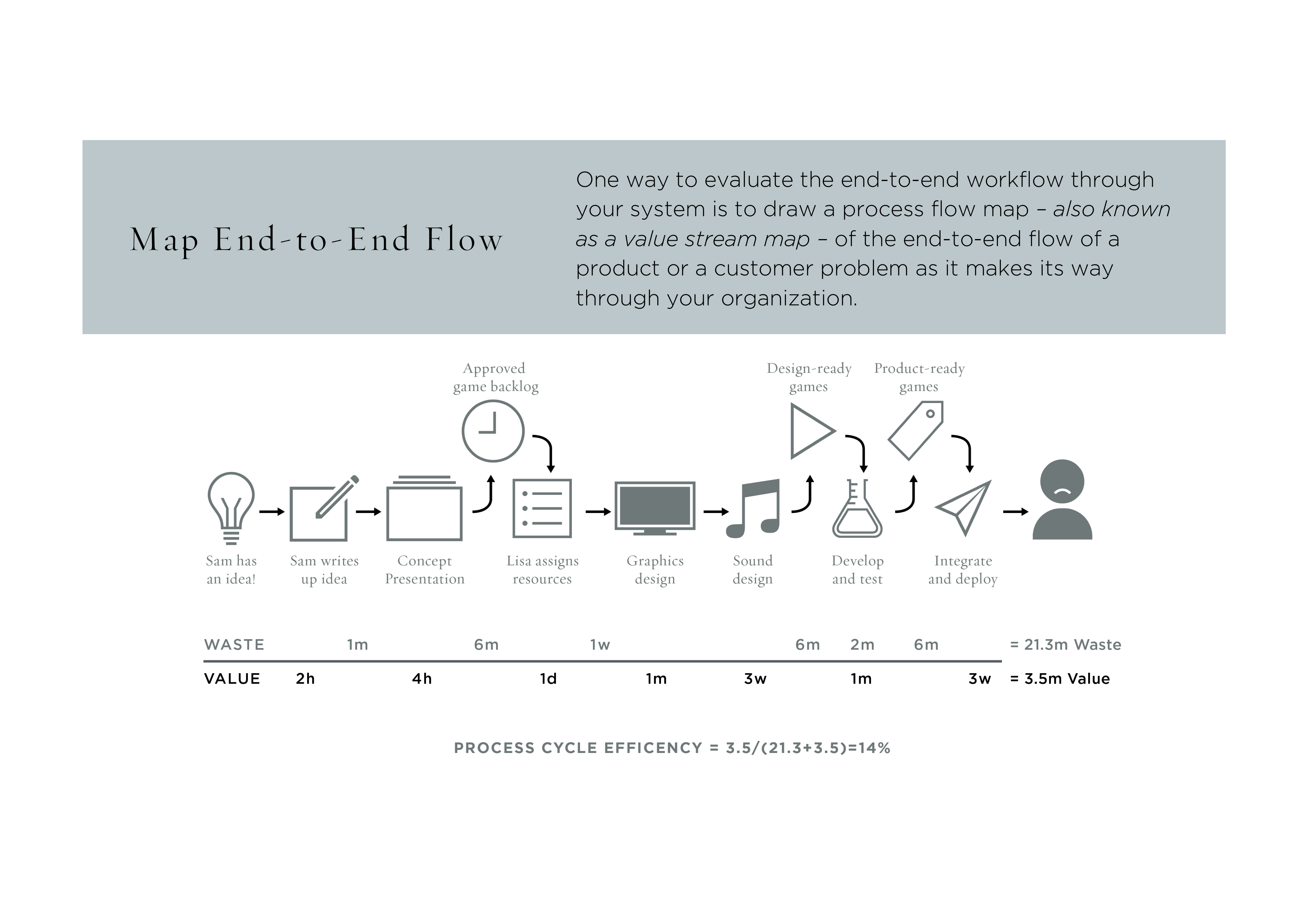 © William Evans | https://www.infoq.com/presentations/agile-self-organizing-teams-design-thinking
© William Evans | https://www.infoq.com/presentations/agile-self-organizing-teams-design-thinking
Den dritten Teil des Vortrags zum Hintergrund von Design Thinking leitete der Referent folgendermaßen ein:
»In practice it combines empathy to enable deep understanding and reframing of a problem in context, divergence to generate insights and solutions; visualization and prototyping to document, connect and test ideas, and rationality to analyze and assess the solutions outcome.« – TIM BROWN, IDEO
Hintergrund sind dabei die Grundlagen von Peter G. Rowe »Design Thinking« aus dem Jahr 1987 und Richard Buchanans »Wicked Problems in Design Thinking« von 1992. Wichtig ist dabei, analog zum Brainstorming, zunächst in einem sogenannten Divergence-Schritt möglichst viele Optionen zu generieren, um im folgenden Convergence-Schritt durch Entscheidungen den Lösungsraum wieder einzugrenzen:
 © William Evans | https://www.infoq.com/presentations/agile-self-organizing-teams-design-thinking
© William Evans | https://www.infoq.com/presentations/agile-self-organizing-teams-design-thinking
Ohne das Problem richtig verstanden zu haben, kann auch keine gute Lösung gefunden werden, denn
»A problem well stated is mostly solved.« — CHARLES KETTERING
Hierzu ist wiederum eine empathische Herangehensweise notwendig, denn in jedem Problem, welches zu uns gebracht wird, steckt die Chance, im Rahmen von Design Thinking etwas zu verbessern.
»The day soldiers stop bringing you their problems is the day you have stopped leading them. They have either lost confidence that you can help or concluded you do not care. Either case is a failure of leadership.« - COLIN POWELL
Was dann alles zusammengefasst zum sogenannten Double Diamond Modell des Design Thinking führt:
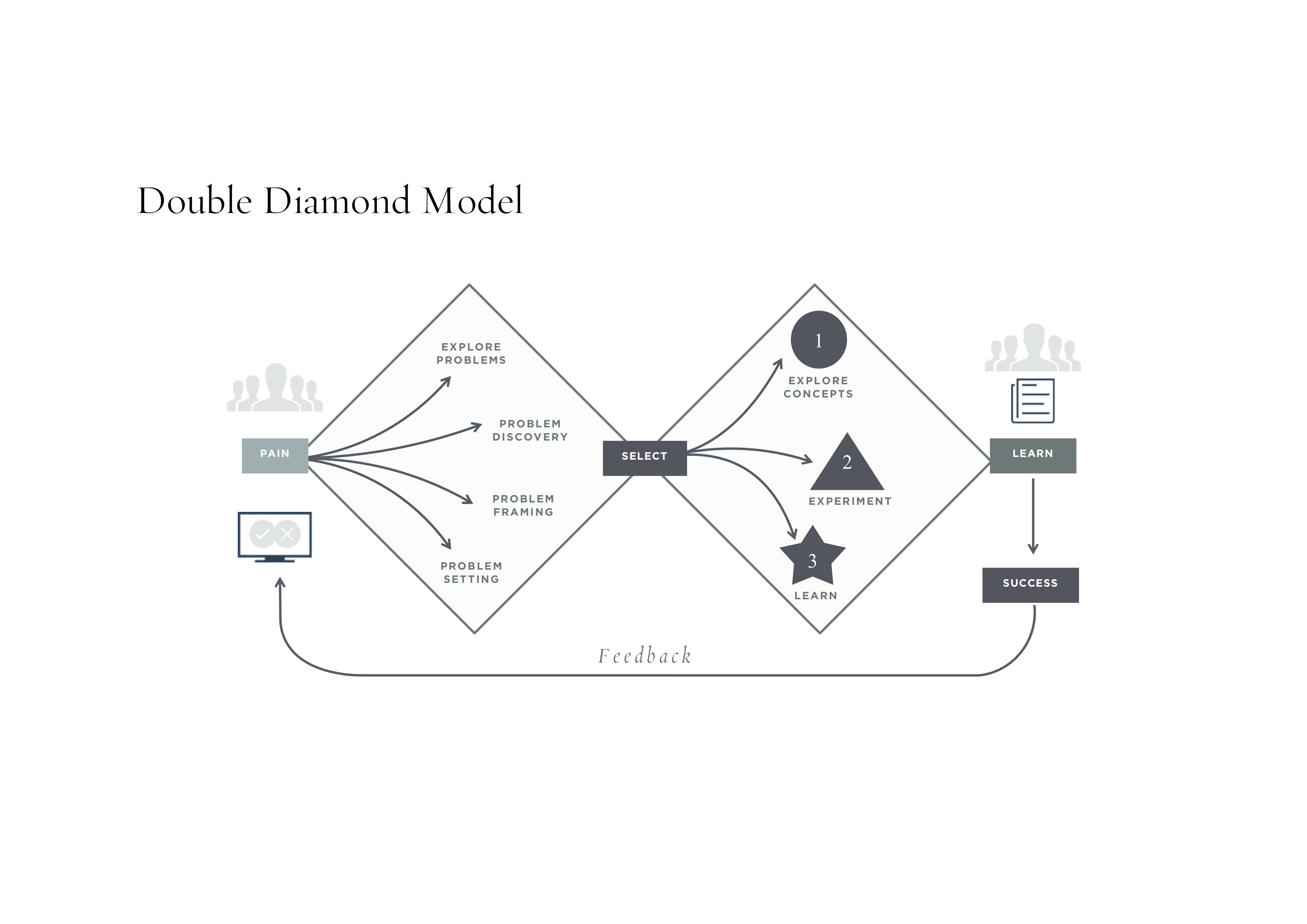 © William Evans | https://www.infoq.com/presentations/agile-self-organizing-teams-design-thinking
© William Evans | https://www.infoq.com/presentations/agile-self-organizing-teams-design-thinking
Software Is Eating the World, ML Is Going to Eat Software
Der Referent dieses Vortrags ist Engineer im Developer Infrastructure Team von Facebook. Der Einblick ins Engineering bei Facebook und dass sie dort überhaupt genau so ein Team haben, welches Tools und Infrastruktur für Entwickler zentral bereitstellt, war dabei gleich die erste interessante Information.
Facebook möchte Machine Learning in jeder Schicht ihres Technologiestacks integrieren, um Entwickler produktiver und Prozesse und Infrastruktur effizienter zu machen. Machine Learning ist dabei für Facebook nur ein weiteres Tool, wie beispielsweise objektorientierte oder funktionale Programmierung, welche auch entsprechend tief in die Programmiersprachen und Entwicklertools, wie zum Beispiel IDEs oder Versionskontrolle integriert wird.
Machine Learning kommt da zum Einsatz, wo viele Daten anfallen, um Vorhersagen abzuleiten und Klassifizierungen sowie Cluster zu bilden. Der Referent nannte dabei zwei konkrete Anwendungsfälle in seinem Umfeld bei Facebook: zum einen das Cache Management in der Infrastruktur und zum anderen die Autovervollständigung ganzer Codeteile in der Entwicklung. Ausgangssituation für Letzteres ist dabei folgende Erkenntnis:
»70 % des Codes auf Github ist Copy & Paste.« – Joe Pamer
Da der meiste Code also sowieso kopiert wird, sollen Entwickler in ihrer IDE, ähnlich zur Autovervollständigung von beispielsweise Schlüsselwörtern der jeweiligen Programmiersprache, Vorschläge für ganze Codeteile, wie zum Beispiel Methoden oder Klassen bekommen, die an die jeweilige Stelle im Code passen könnten. Das geht dann über einfache Code-Suche, wie wir zum Codesharing mit Tools wie Sourcegraph und Searchcode skiziiert haben, hinaus und schon mehr in Richtung Deep Code Search, aber eben auf Basis der umfangreichen Codebasis von Facebook und mit Machine Learning, da Code ja auch nur strukturierte Daten sind. Mit diesem Ansatz konnte die Produktivität der Entwickler bei Facebook bereits um 14 % gesteigert werden. Bei geschätzten 10.000 Entwicklern, die für Facebook arbeiten, ist dies ein erheblicher Produktivitätsgewinn.
Einschätzung
Die Workshops waren unserer Einschätzung nach nicht ganz »bleeding-edge«, die Keynotes und Vorträge durchaus. Wobei die New Yorker QCon auf uns insgesamt etwas kleiner und vermutlich da eben nicht im Silicon Valley gelegen, auch nicht ganz so pulsierend wie die Veranstaltung in San Francisco gewirkt hat. Egal wo, die Veranstaltungen sind immer einen Besuch wert, denn auch wenn es heutzutage eigentlich dafür keinen Grund mehr geben sollte, so sind die Themen hier entsprechenden Veranstaltungen in Deutschland dann doch immer noch ein Stück voraus.