Übersicht relational und/oder noSQL (Teil 2): Daten-Modellierung in den beiden Welten.

Nach der grundsätzlichen und eher theoretischen Betrachtung der zwei Datenbank-Modelle vergleichen wir hier die Datenmodellierung in den beiden Welten anhand eines konkreten Beispiels (Blog-Systems mit Benutzern, Blog-Einträgen, Kommentaren und Markierungen).
In der relationalen Datenbank-Welt ist das Ziel Normalisierung zur Vermeidung von Daten-Redundanzen. Dementsprechend wird das Blog-System hier in seine »üblichen« Bestandteile zerlegt:
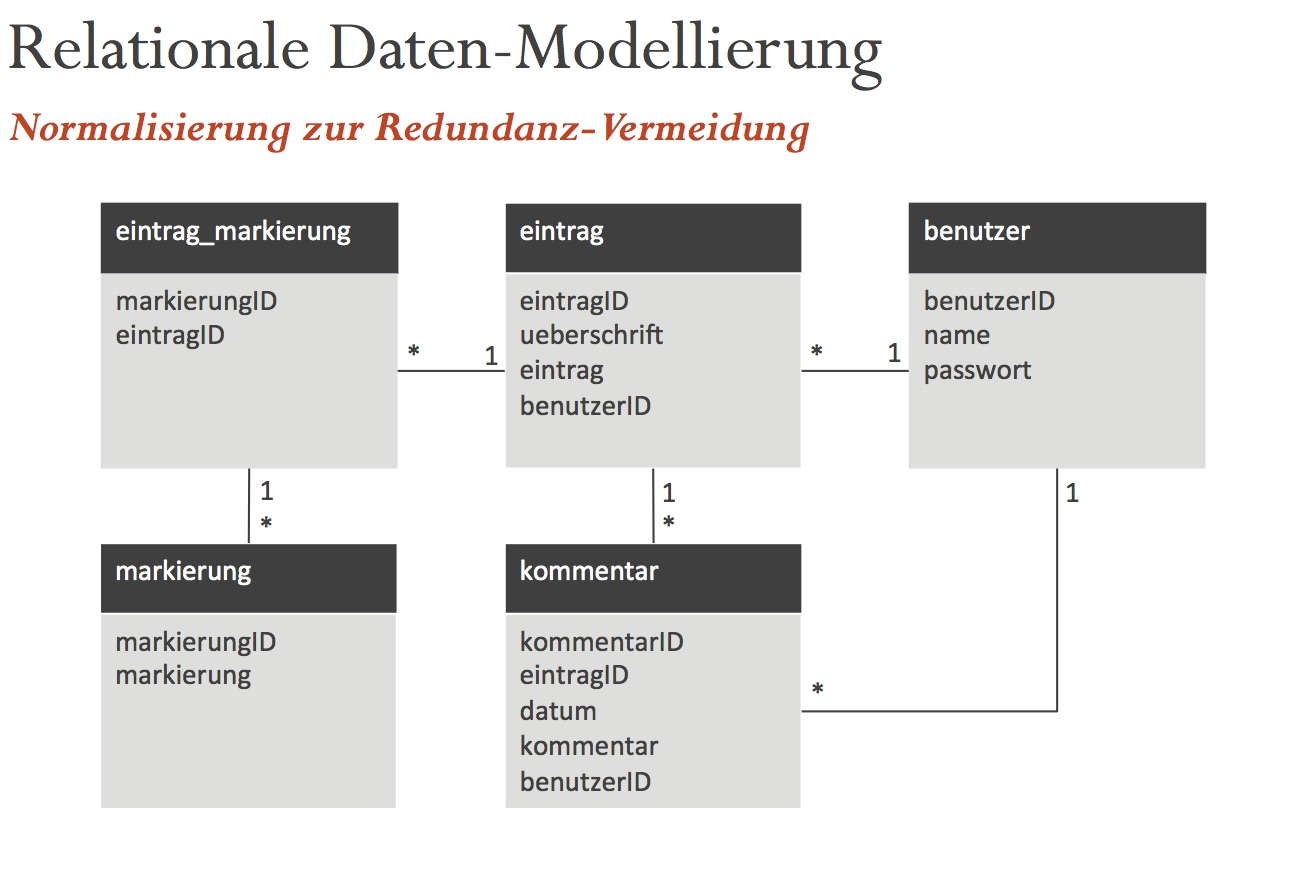
Die Redundanz wird vermieden, in dem die Daten über mehrere Tabellen verteilt werden, welche zur Laufzeit bei entsprechenden Abfragen wieder zusammengeführt werden. Um herauszufinden, dass der Blog-Eintrag »1« bspw. als »Nachricht« markiert ist, müssen die Daten aus den drei Tabellen (eintrag, eintrag_markierung und markierung) zusammengeführt werden (»join«).
Anders hingegen in der noSQL-Welt, hier sind Redundanzen und Denormalisierung gewollt, damit die verschiedenen »Aggregate« unabhängig voneinander sind und somit insb. auch unabhängig verwaltet werden können. Der Begriff des »Aggregats« geht auf Eric Evans’ Domain Driven-Design zurück und wurde von Martin Fowler dann in die NoSQL-Daten-Modellierung übertragen.
Aggregate werden immer als Gesamtheit behandelt, d. h. vollständig (atomar) gespeichert oder gelesen, auch wenn nur Teilaspekte benötigt werden. Somit können innerhalb eines Aggregats keine Konsistenzprobleme auftreten.
Kernfrage bei der Aggregat-orientierten Modellierung ist, welche Abfragen auf die Daten später vorkommen. Im Blog-Beispiel wird die Anwendung sehr häufig alle Informationen zu einem Blog-Eintrag benötigen, um den Eintrag als Ganzes, inklusive Autorinformation und Kommentaren, darzustellen. Außerdem wird eine Benutzerverwaltung benötigt.
Deshalb bietet es sich in der noSQL-Welt an, zwei entsprechende Aggregate (oder auch Collections) namens »Einträge« und »Benutzer« zu modellieren. Ein einzelner Blog-Eintrag würde in einer noSQL-Datenbank als Dokument in JSON-Notation folgendermaßen vorgehalten:
Beispiel 1: Aggregat / Collection: »Einträge«
{"xd": 1,
"autor": "Michael",
"datum": "2015-03-23T11:19:21.000Z",
"ueberschrift": "Mein neuer Blog",
"eintrag": "Hier der Text des Blogs…",
"markierung": ["Allgemein", "News"],
"kommentare": [{
"autor": "klaus1",
"datum": "2015-03-24T11:23:15.000Z",
"kommentar": "Super Blog!"
},{
"autor": "tom15",
"datum": "2015-03-25T11:29:15.000Z",
"kommentar": "Unbedingt lesen!"
}],
"id": 2,
"autor": "Oliver",
...
}Beispiel 2: Aggregat / Collection: »Benutzer«
{"benutzer": "Michael",
"name": {
"vorname": "Michael",
"nachname": "Schwarze"
},
"password": "$5$6&7665!!223/34%4",
"benutzer": "tom15",
...
}Die im relationalen Modell vorhandenen Verknüpfungen sind hierbei aufgelöst. Um einen Blog-Eintrag anzuzeigen, muss in diesem Modell nur ein einziges Dokument aus der Datenbank geladen werden. Joins entfallen; sie sind in noSQL-DBMS nicht erwünscht bzw. auch z.T. gar nicht möglich. Soll zusätzlich zum Benutzer auch sein Nachname angezeigt werden, muss die Applikation den (gesamten) Datensatz des Benutzers aus der zweiten Collection lesen und das Feld entsprechend hinzufügen. Sollte diese Information regelmäßig in der ersten Collection benötigt werden, sollte das Aggregat ggf. entsprechend angepasst werden; Schema-Änderungen haben hier ja ihren Schrecken verloren.
Wie immer ist nichts umsonst und die Vorteile auf der einen Seite bedingen Abstriche an anderer Stelle. Die (gewollte) Redundanz bedingt, dass Änderungen an diesen redundanten Daten entsprechend verteilt werden müssen. Hierzu haben sich bereits Entwurfsmuster (Replikation, Feed, …) etabliert, welche wir in einem gesonderten Beitrag beleuchten werden.
Am Beispiel der Daten-Modellierung für eine einfache Applikation in den beiden Datenbank-Welten wird deutlich, dass noSQL nicht nur eine andere DB-Technik, sondern ein anderes Datenbank-Paradigma ist und ein Umdenken im gesamten Software-Entwicklungsprozess (Design, Entwicklung, Betrieb) nach sich zieht.