Übersicht relational und/oder noSQL (Teil 1): Die zwei Datenbank-Modelle im Vergleich.
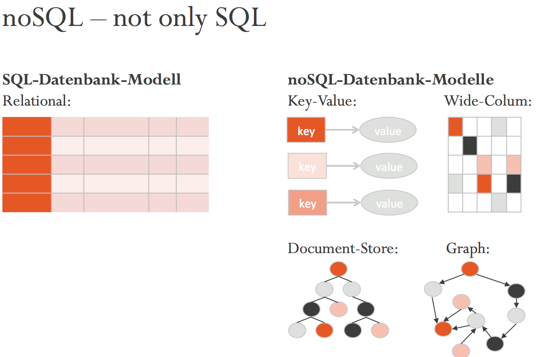
Lange Zeit stellte sich die Frage nach dem einzusetzenden Datenbank-Modell aufgrund der dominanten Stellung der relationalen Datenbank-Management-Systeme (DBMS) und dem Mangel an Alternativen gar nicht. Objekt-relationale Datenbanken existierten zwar, aus Gründen der betrieblichen / administrativen Vereinfachung kamen dann aber doch meist relationale DBMS, ggf. mit einem entsprechenden objekt-relationalen Mapper wie bspw. Hibernate zum Einsatz.
Mit dem vermehrten Aufkommen von alternativen Datenbank-Modellen wurde die Diskussion dann zunächst häufig ideologisch statt sach-orientiert geführt, weshalb eine Definition und Abgrenzung hilfreich ist. Wir verwenden den Begriff noSQL entsprechend im Sinne von »not only SQL» als Sammelbegriff für zum relationalen Modell »alternative« Datenbank-Modelle, insb. Key-Value- und Document-Stores, aber auch Wide-Column-Stores und Graph-Datenbanken. NoSQL bezeichnet also nicht EIN zum relationalen DB-Modell orthogonal stehendes Modell, sondern vereinigt MEHRERE verschiedene, nicht-relationale Ansätze.
Typische Einsatzszenarien für Key-Value-Stores sind Problemstellungen mit Fokus auf höchster Performance und/oder extremer Skalierbarkeit. Extended-Column Stores werden häufig verwendet, wenn die Daten eine gewisse Hierarchie besitzen, auf deren Einzelattribute gesondert zugegriffen werden soll. Dokumentendatenbanken bieten als Allzweck-Datenbanken einen ausgewogenen Featuremix. Graphendatenbanken ermöglichen darüber hinaus die Modellierung und Abfrage komplexer Beziehungen.
NoSQL-Datenbanken haben sich u.a. aus der Problematik beim (horizontalen) Skalieren relationaler DBMS entwickelt. Insb. Webanwendungen mit einer Vielzahl von gleichzeitigen Zugriffen kommen bei relationalen DBMS häufig an ihre Grenzen bzw. der Administrationsaufwand steigt bei diesem Datenbank-Modell überproportional mit den Zugriffen; die Datenbank kann hier zum Flaschenhals werden. NoSQL-Datenbanken können dieses Problem erfolgreich lösen – aber nicht »umsonst«; wie so häufig »erkauft« man sich den »Gewinn« an der einen Stelle (Performance, Skalierung) durch Zugeständnisse an anderer Stelle (Transaktionssicherheit, Konsistenz der Daten).
Das Datenmodell, also Aufbau und Abhängigkeiten der Zeilen und Spalten untereinander, wird insb. im relationalen Ansatz in der Datenbank gehalten. Änderungen an diesen Datenstrukturen sind hier aber aufwendig und »teuer« (ALTER TABLE, Migration, etc.). Falls sich das Datenmodell also häufig ändert, können schema-lose noSQL-Ansätze sinnvoll sein. Die Datenstruktur verlagert sich hier in die Applikation bzw. deren Source-Code, wo der Entwickler Änderungen mit den ihm geläufigen Mitteln (Code-, Schnittstellen-Service-Versionierung) entsprechend besser verwalten kann. Aber auch hier gibt es natürlich Einschränkungen, die ein Umdenken erfordern, denn das Datenmodell lässt sich dann auch nicht mehr auf »klassischem« Wege aus der Datenbank ermitteln, sondern ist ggf. in der Applikation »versteckt«. Was andererseits wiederum durchaus gewollt sein kann, da in gewissen Architekturansätzen (bspw. Microservices) ausschießlich über entsprechend definierte Schnittstellen exponiert wird und Wissen über die internen Datenstrukturen einer Applikation auch intern bleiben kann und soll. Nur müssen diese Schnittstellen dann entspechend dokumentiert werden; eine schema-lose Datenbank übernimmt den Job nicht.
Ein weitere Fragestellung, die es bei der Wahl des Datenbank-Modells zu beantworten gilt, dreht sich um die Transaktionssicherheit sowie Datenkonsistenz. Beides Merkmale, bei denen SQL-Datenbanken strukturell ihre Vorteile ausspielen. Hierbei muss allerdings zwischen technischer und fachlicher Transaktion differenziert und der notwendige Grad der Datenkonsistenz kritisch hinterfragt werden. Ein zugegebenermaßen vielzitiertes Beispiel ist die Überbuchungsregelung bei Fluggesellschaften: da es technisch unverhältnismäßig aufwendig wäre, die vielen verteilten Buchungssysteme und -anfragen zu synchronisieren, lässt man es zu, dass es zu Überbuchungen kommen kann und behandelt das Problem dann fachlich im Einzelfall, wenn es auftritt, durch entsprechende Umbuchung, Upgrade, etc.. Was übrigens grundsätzlich eine gute Idee ist, denn nicht alles, was technisch machbar ist, muss auch zwangsläufig technisch gelöst werden!
Bei der Fragestellung rund um die Konsistenz von Daten in verteilten Systemen kann die Auseinandersetzung mit dem CAP-Theorem hilfreich sein. Es besagt, dass in einem verteilten System von den drei Anforderungen Konsistenz (Consistency), Verfügbarkeit (Availability) und Partitionstoleranz nur zwei umfassend erfüllt werden können:
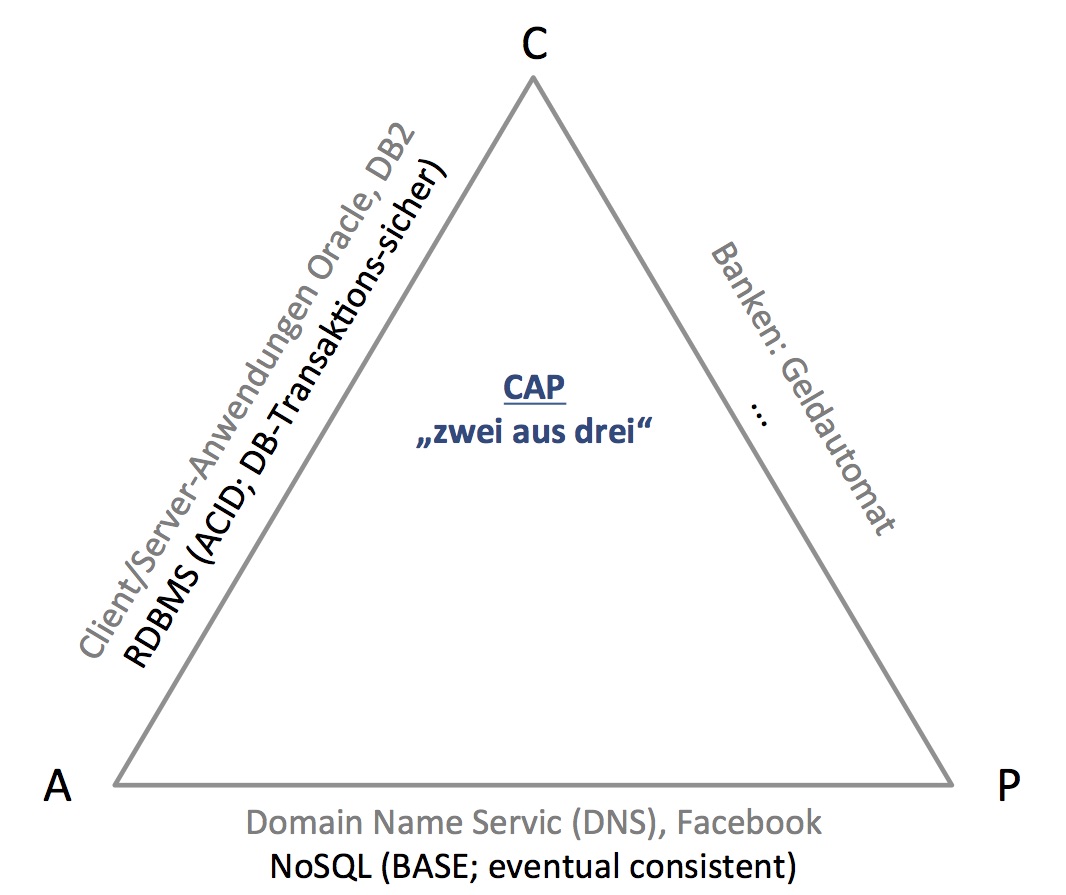
Hierbei kann grob festgehalten werden: Liegt der Fokus des Anwendungsfalls eher auf Verfügbarkeit und Konsistenz, so empfiehlt sich ein relationaler Ansatz. Liegt der Schwerpunkt hingegen auf Partitionstoleranz und Verfügbarkeit, so empfiehlt sich ein noSQL-Ansatz.
Ein weiteres mögliches Kriterium zur Auswahl des für den Anwendungsfall jeweils optimalen Datenbank-Modells liegt in der Häufigkeit der Lese- und Schreiboperationen. Die Modellierung beim noSQL-Ansatz führt zwangsläufig zu Redundanzen; dies ist gewollt, unter anderem, um die potentiell vielen Lesezugriffe zu optimieren. Dies führt aber zu »teuren« Schreibzugriffen im noSQL-Ansatz. Viele Lesezugriffe werden also in der noSQL-Welt begünstig, viele Schreibzugriffe eher in der relationalen Welt.
Die unter dem Begriff noSQL sub-summierten Datenbank-Modelle wurden entwickelt, um unterschiedliche Datenbankprobleme, welche mit einem relationalen Datenbanksystem nicht oder nicht ganz gelöst werden können, zu lösen. Wie bei jedem Werkzeug gilt auch hier, dass es Einsatzzwecke für das eine und für das andere Modell gibt; »manchmal braucht es einen Hammer und manchmal einen Schraubendreher«.
Als grobe Entscheidungshilfe für die eine oder andere Welt kann die folgende Zusammenfassung dienen:
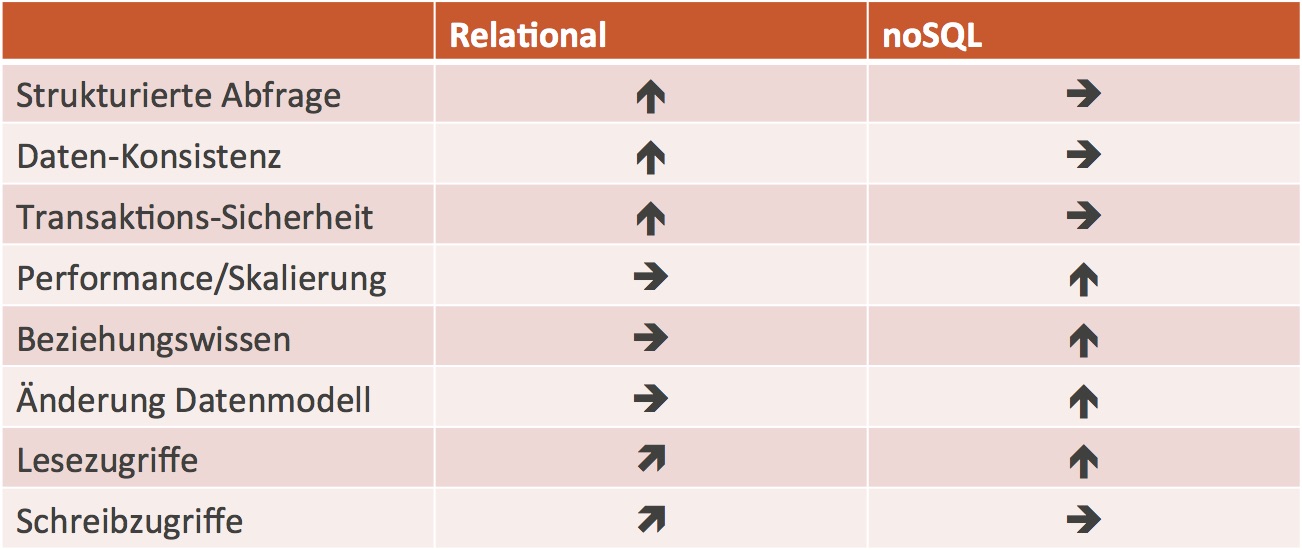
Wird eine strukturierte Abfragemöglichkeit benötigt, wenn Daten-Konsistenz oder Transaktions-Sicherheit eine Rolle spielen oder tendentiell eher schreibende Datenzugriffe vorliegen, dann ist dies ein Indiz für den Einsatz eines relationalen DBMS.
Dreht es sich um Performance/Skalierung (im Web-Maßstab), die Abbildung von Beziehungswissen oder erfolgen eher Lesezugriffe und häufige Änderungen am Datenmodell, dann spricht dies für noSQL-Datenbanken.
Es empfiehlt sich, auf Basis des jeweiligen Anwendungsfalls, die Entscheidung für oder gegen ein Datenbank-Modell zu treffen. Im Zweifelsfalls ergeben sich somit sogar unterschiedliche Datenbank-Modelle für die unterschiedlichen Anwendungsfälle einer Applikation – ganz im Sinne von Eric Evans’ Domain Driven-Design; mit all seinen (betrieblichen) Herausforderungen…
Einen praktischen Einblick in die konkrete Datenmodellierung in den beiden Welten gibt es im zweiten Teil des Artikels.