Statistische Abfragen auf Githubs Datenbasis waren über deren Web-API bisher nur bedingt möglich. Googles Cloud Platform bietet seit Juni Zugriff u.a. per SQL auf die aktuell rund 3 TB (!) umfassende Open-Source-Software (»OSS«) Code-Basis von Github, wodurch sich ganz neue Anwendungsfälle zur Code-Analyse ergeben. Wir stellen die beiden Ansätze und einige Erkenntnisse im folgenden Artikel vor.

GitHub ist mit über 12 Millionen Entwicklern und 31 Millionen Projekten (»Repositories«) Heimat der größten OSS-Gemeinschaft der Welt. Google bietet diverse Cloud-Dienste an, bspw. auch Zugriff auf verschiedenste öffentliche Daten, wie z.B. demografische und wirtschaftliche Indikatoren von EUROSTAT, der OECD, etc. – und seit Kurzem eben auch Github-Daten.
Github-API
Über eine entsprechende http-API lässt sich der Datenbestand von Github bereits seit längerem direkt an der Quelle abfragen. Die URLs aller Repositories eines entsprechenden Github-Benutzers liefert bspw. folgender Aufruf mit curl, dem Bordwerkzeug vieler Betriebssysteme für http-Abfragen; Postman o.ä gehen natürlich auch:
curl -i https://api.github.com/users/testuser/reposHTTP/1.1 200 OK
…[
{
"id": 39790,
"name": "haml-test",
"full_name": "testuser/haml-test",
"owner": {
"login": "testuser",
"id": 19480,
"avatar_url": "https://avatars.githubusercontent.com/u/19480?v=3",
"gravatar_id": "",
"url": "https://api.github.com/users/testuser",
"html_url": "https://github.com/testuser",
…
"type": "User",
"site_admin": false
},
"private": false,
"html_url": "https://github.com/testuser/haml-test",
"description": "Test",
"fork": false,
…
"default_branch": "master"
},
{
"id": 34541627,
"name": "wwwsqldesigner",
"full_name": "testuser/wwwsqldesigner",
…
"default_branch": "master"
}
]Es handelt sich um eine ressourcen-zentrische REST-API, deren Fokus auf programmatischer Weiterverarbeitung der Ergebnisse entsprechender Abfragen liegt. Somit sind statistische Ad-hoc-Auswertungen über größere Datenmengen nur eingeschränkt möglich. Hinsichtlich der Auswertung von Sourcecode über die Github-API gibt es weitere Beschränkungen. So wird bspw. nur der Standard-Branch, in den meisten Fällen also der master berücksichtigt. Außerdem werden nur Quellcode-Dateien kleiner als 348 kB in die Suche einbezogen; was allerdings auch aus Coding-Style-Gründen hoffentlich nicht zu oft vorkommen sollte…
Einfache Abfragen wie die absolute Anzahl der Fehler in Python, Ruby oder Java sind unproblematisch möglich:
curl -i https://api.github.com/search/issues?q=label:bug+language:ruby | grep "total_count"
#=> 96.725
curl -i https://api.github.com/search/issues?q=label:bug+language:python | grep "total_count"
#=> 222.147
curl -i https://api.github.com/search/issues?q=label:bug+language:java | grep "total_count"
#=> 255.229Die Zahlen sind alleine natürlich noch nicht sehr aussagekräftig. Die Fehler müssen ins Verhältnis zu einer entsprechenden Basisgröße gebracht werden, also bspw. den Lines of Code, der Größe der Repositories o.ä.. Die Anzahl Repositories je Sprache lässt sich über die API relativ leicht mitteln:
curl -i https://api.github.com/search/repositories?q=language:ruby | grep "total_count"
#=> 1.062.856
curl -i https://api.github.com/search/repositories?q=language:python | grep "total_count"
#=> 2.156.797
curl -i https://api.github.com/search/repositories?q=language:java | grep "total_count"
#=> 1.171.524Diese Art von Abfragen machen sich bspw. auch Programmiersprachen-Rankings zunutze, um anhand der Anzahl der Repositories einer Sprache auf ihre Beliebheit zu schließen.
Hinsichtlich der relativen Fehleranzahl je Programmiersprache ergibt sich somit folgendes Bild:
| Sprache | Fehler | Repositories | Fehler / Repository |
|---|---|---|---|
| Ruby | 96.725 | 1.062.856 | ~0,09 |
| Python | 222.147 | 2.156.797 | ~0,13 |
| Java | 255.229 | 1.171.524 | ~0,22 |
Ein Schelm, wer hier Böses denkt und von der doppelten Anzahl an Fehlern in Java gegenüber Ruby und Python Rückschlüsse etwa auf das jeweilige Typsystem (statisch vs. dynamisch) macht. Dies werden wir in einem separaten Artikel näher beleuchten. Vielleicht liegt es auch an den Lines-of-Code, komplexeren Anwendungen oder daran, dass Java-Entwickler einfach mehr Fehler in Github eröffnen…
Die Github-API ist eine REST-Schnittstelle, die Ressourcen und keine statistisch Operationen auf dispositive Daten anbietet. Für komplexere Auswertungen über größere Code-Bestände müsste man bspw. über die API soweit es geht die Repositories eingrenzen, selbige dann mittels weiterer Requests forken, um diese dann lokal analysieren zu können – alles machbar, aber für eher explorative BigData-Analysen doch etwas unhandlich…
BigQuery
Hier kommt nun seit kurzem Google ins Spiel. Über ihre vormals interne Cloud Plattform bieten sie schon seit längerem diverse kommerzielle Cloud-Dienste im infrastrukturnnahen Bereich an. Es handelt sich bspw. um Lösungen im Umfeld Hosting, Computing, Cloud-Speicher, diverser APIs, etc., also vergleichbar mit Amazons AWS oder Microsofts Azure.
Ein Baustein innerhalb von Googles Cloud-Diensten ist die BigData-Architektur, mittels der sich große Datenmengen einlesen, speichern, transformieren und auf diversen Wegen (API, SQL, BI-Tools, etc.) analysieren lassen:
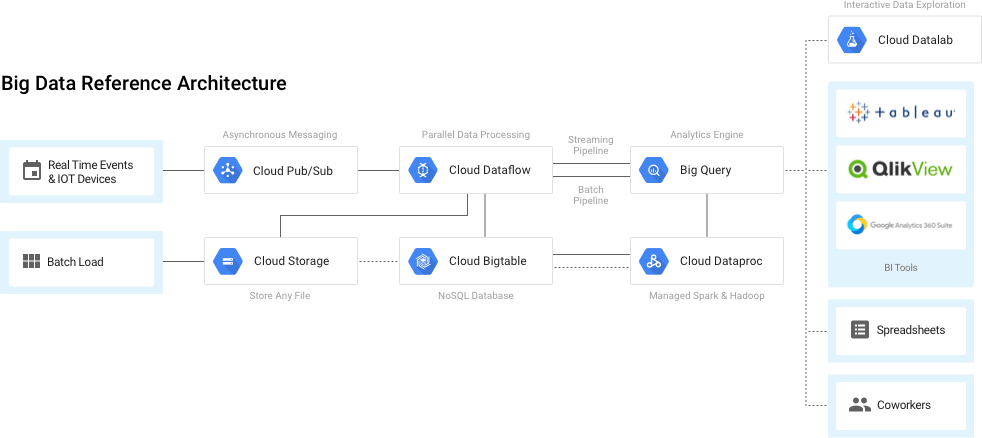
(Quelle: Google)
{kind=link}
BigQuery ist das Data Warehouse innnerhalb von Googles BigData-Angebot zur interaktiven Analyse von großen Datenmengen. Jeder kann hier Daten einstellen und entweder einer geschlossenen Benutzergruppe oder eben auch öffentlich zugänglich machen. In letzterem Fall spricht Google dann von den sog. Public Data Sets. Hier finden sich mittlerweile interessante Daten von historischen Wetteraufzeichungen über Geburtsdaten bis zu allen jemals auf HackerNews erschienenen Artikeln. Oder eben nun die gesammelten Github-Sourcen nebst aller begleitenden Metadaten.
Githubs Public Data Set in Googles Cloud Platform umfasst mehr als 3 TB an Daten, verteilt auf 2,8 Millionen Repositories mit mehr als 145 Millionen Commits und dem Inhalt der aktuellsten Revision von mehr als 163 Millionen Dateien; alle mittels regular Expression durchsuchbar. Das Data Set wird derzeit wöchentlich aktualisiert. Abrufbar ist es auf verschiedenste Weisen, Ad-hoc-Anfragen lassen sich am einfachsten direkt über die SQL-Konsole ausführen. Daran, dass einfache Abfragen auf 100 GB und mehr innerhalb von wenigen Sekunden erledigt sind, merkt man, dass Google so einiges an Infrastruktur im Hintergrund diese Dienstes im Einsatz hat.
Die Laufzeit ist also weniger problematisch, eher die Quotierung der Abfragen: die monatlich freien 1 TB sind auf dem Datenbestand schnell abgefragt…Google stellt allerdings auch reduzierte Datensets auf den Bestand zur Verfügung: [bigquery-public-data:github_repos.sample_contents] enthält bspw. »nur« rund 23 GB an Daten. Hier lassen sich entsprechende Abfragen zunächt gefahrlos ausprobieren, bevor man sie dann auf den gesamten Bestand ansetzt. Außerdem wird einem zumindest in der Konsole vor jeder Abfrage angezeigt, wie viele Daten verarbeitet würden, so dass man sich also immer noch überlegen kann, ob es das einem Wert ist.
Die Anwendungsmöglichkeiten, welche sich aus der Analyse des gesammelten Open-Source-Softwarebestands von Github ergeben, sind immens. So ließen sich statische Code-Analyse-Tools oder Code-Style-Guides auf Basis entsprechender Best-Practice kalibrieren. Als OSS-Anbieter kann ich mir einen Überblick über den Einsatz meiner Software verschaffen und so bspw. die Auswirkungen von Änderungen meiner API besser einschätzen. Im wissenschaftlichen Bereich lassen sich entsprechende Hypothesen aus dem Software-Engineering nun gegen Millionen »echter« Codezeilen validieren; das o.g. Beispiel bzgl. der Fehlerhäufigkeit in verschiedenen Programmiersprachen stellt da nur ein triviales Beispiel dar.
Andererseits eröffnen sich natürlich auch »interessante« Möglichkeiten für Hacker. Eine gezielte Abfrage, welche Open-Source-Software bspw. noch eine veraltete Version einer Bibliothek mit bekannten Sicherheistlücken einsetzt, ist genauso unproblematisch möglich, wie die Suche nach offenliegenden Zugangsdaten.
Die folgende Abfrage zählt bspw. das Vorkommen von »password =« im Beispieldatenbestand:
SELECT
SUM(copies)
FROM
[bigquery-public-data:github_repos.sample_contents]
WHERE
NOT binary
AND content CONTAINS 'password ='
#=> 154.634Die Abfrage braucht 5 Sekunden für die rund 23 GB Daten. Auch wenn dank CONTAINS sicherlich ein entsprechender Index im Einsatz ist, so ist dass keine schlechte Leistung bei einer Volltext-Suche über diese Datenmenge.
Dass im o.g. Beispiel 154.634 Mal der Variablen password ein Wert, bspw. aus einem entsprechenden Eingabeformular zugewiesen wurde, ist an sich keine Besonderheit. Dass im dritten gefundenen Repository dieser Abfrage dann gleich ein entsprechendes Passwort im Klartext einsehbar ist, verwundert schon mehr, ist aber erwartungsgemäß: ein initial direkt im Quellcode, einer Konfigurations- oder Testdatei liegendes Passwort ist schnell auf Github eingecheckt – und somit auch in der Commit-Historie. Dass das Internet nichts vergißt, gilt also auch hier. Umso wichtiger ist es, sich vor dem ersten Push Gedanken darüber zu machen, wo ggf. sicherheits-relevante Daten im Code stecken und diese entsprechend zu behandeln (.gitignore, etc.).
Ein Werkzeug lässt sich immer sowohl für gute als auch weniger gute Dinge einsetzen: der Hammer hilft beim Nägel in die Wand bringen genauso, wie beim Einschlagen einer Scheibe. Die Vorteile aus den neuen Analysemöglichkeiten auf den Datenbestand von Github mittels Googles BigQuery überwiegen unserer Einschätzung nach die skizzierten Nachteile. Letztendlich handelt es sich um die konsequente Weiterführung des Open-Source-Gedanken, welcher bereits zu erhebliche sicherer Software geführt hat.
Wir sind gespannt, welche konkreten Anwendungsfälle hier in nächster Zeit entstehen werden, bspw. auch aus der Verknüpfung von den Github-Daten mit anderen öffentlichen Datenquellen…